PLaMo 3.0 Primeとは?PFN国産フルスクラッチLLMの料金・256Kコンテキスト・使い方を徹底解説

この記事のポイント
PLaMo 3.0 PrimeはPFNがフルスクラッチ開発した国産生成AI基盤モデル。256Kコンテキスト・Reasoning/Non-reasoning 2系統・無料APIプラン・料金・使い方・デジタル庁源内採用までを公式情報ベースで整理します。
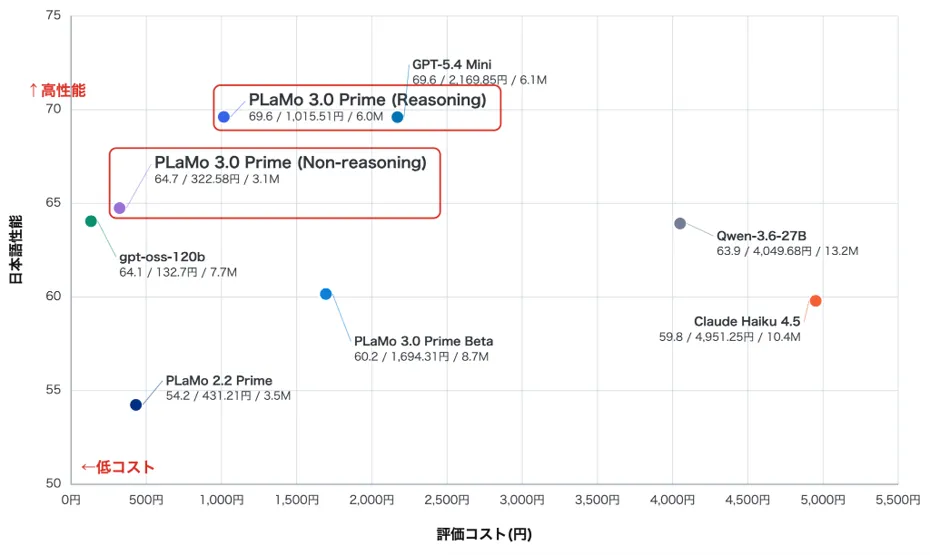
PLaMo 3.0 Prime(プラモ・スリー・ゼロ・プライム)は、株式会社Preferred Networks(PFN)がアーキテクチャから学習まで完全自社開発した「国産フルスクラッチ」の生成AI基盤モデル(大規模言語モデル)です。 2026年6月22日にβ版から正式版(GA)となり、256Kトークンの長文処理、用途で切り替えられるReasoning/Non-reasoningの2系統、無料で試せるAPIプランを備えています。
この記事では、PLaMo 3.0 Primeの定義・できること・料金・使い方・他モデルとの違い・導入時の注意点を、PFN公式リリースとヘルプセンターの情報をベースに整理します。海外モデルの派生ではなく日本語に最適化された純国産モデルである点、そして「Reasoningを使うとコストが跳ね上がる」といった実務上の落とし穴まで踏み込んで解説します。
この記事でわかること:
- PLaMo 3.0 Primeの正体と「フルスクラッチ国産」が意味すること
- Reasoning/Non-reasoning 2系統の使い分けと256Kコンテキストの実力
- Free / Standard / Provider の料金プランと無料キャンペーンの条件
- OpenAI互換APIでの使い方(モデルID・
reasoning_effort) - 海外フロンティアモデルとの違い、向いている企業・向いていない企業
想定読者は、社内システムやAIエージェントに組み込む国産LLMを検討しているエンジニア・情報システム担当者、機密データを外に出せない官公庁・金融・医療の導入検討者、そしてコストと日本語性能を重視する事業者です。
出典: Preferred Networks 公式プレスリリース
PLaMo 3.0 Primeとは何か:純国産フルスクラッチLLMの正体
PLaMo 3.0 Primeは、PFNが海外モデルをベースにせず、アーキテクチャ・トークナイザー・事前学習・事後学習までをすべて自社で設計・実装した国産の大規模言語モデルです。 いわゆる「フルスクラッチ開発」であり、既存の海外オープンモデルをファインチューニングしただけの派生モデルとは出自が異なります。
正式版(GA)のリリース日は2026年6月22日。同年3月に公開されたβ版(PLaMo-3.0-Prime-β)からの正式昇格で、コンテキスト長の拡張やNon-reasoningモデルの追加、ツール利用・コーディング・構造化出力・安全性の強化が行われました。
開発の背景には2つの公的プロジェクトがあります。
- GENIAC(Generative AI Accelerator Challenge)第3期: 経済産業省・NEDOによる生成AI開発支援プログラム。ここでの事後学習成果が反映されています。
- 情報通信研究機構(NICT)との共同研究: 事前学習データセット、安全性データ、医療分野データの拡充で協力。これが日本語性能と安全性、医療ドメインの強さにつながっています。
「国産LLM」という言葉は、2026年4月に楽天のRakuten AI 3.0が海外モデルのリブランドだったとして議論を呼んだ件以降、定義そのものが厳しく問われるようになりました。その文脈で、PLaMo 3.0 Primeが「設計から学習まで自社」というフルスクラッチである点は、国産LLMとしての性格を明確にする重要なポイントです。
なお、モデルの提供形態は次の3通りで、本体(Prime)はクローズドモデル(重み非公開)です。
- PLaMo Chat: Webブラウザで使えるチャットUI
- PLaMo API: OpenAI互換のAPI。本記事の中心
- オンプレミス提供: 閉域環境での運用契約
加えてAmazon Bedrock MarketplaceやSnowflakeへの対応も告知されています。PFNはbaseモデル(plamo-3-nict-2b-base / 8b-base / 31b-base)をHugging Face(pfnet)で公開していますが、これらは事前学習段階のオープンモデルで、Prime本体とは別物です。ローカルで重みを完全に自前運用したい場合はbaseモデルかオンプレ契約が前提になります。
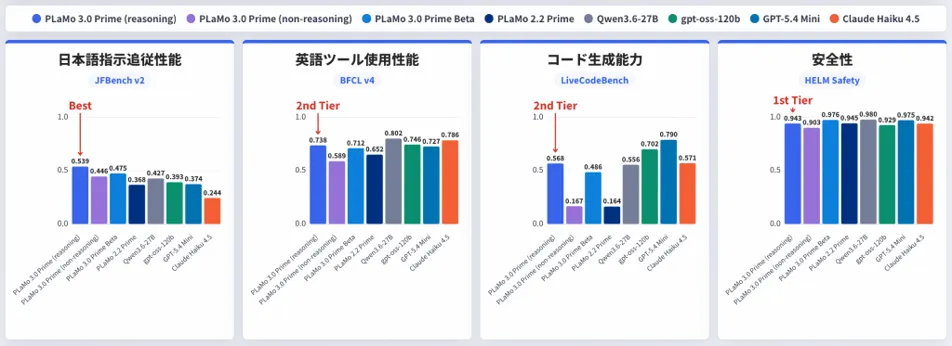
PLaMo 3.0 Primeでできること(主な機能)
PLaMo 3.0 Primeは、長文の読み込み・段階的な推論・外部ツール連携・構造化出力までをカバーする業務向けのLLMです。 主な機能を整理します。
機能 | 内容 |
|---|---|
256Kコンテキスト | 一度に約25万6,000トークン(日本語で約8万字=A4約160ページ相当)を処理。β版の64Kから大幅拡張 |
Reasoning / Non-reasoning 2系統 | 長考型と高速応答型を用途で切り替え |
OpenAI互換API | 既存のOpenAI SDKやツールをほぼそのまま流用可能 |
Tool calling | 外部ツール・関数呼び出しに対応(OpenAIフォーマット) |
構造化出力 | JSONなど決まった形式での出力に対応し、システム連携が容易 |
コード生成・修正 | コーディング用途を強化。AIエージェント用途を想定 |
日本語最適化トークナイザー | 日本語の消費トークンが海外モデルより少なく、コスト効率が高い |
256Kトークンの長文処理
コンテキスト長は256K(約25万6,000トークン)。長い契約書や仕様書、複数の社内文書をまとめて読ませても文脈を保てます。第三者試算では日本語で約8万字、A4で約160ページ相当に当たります。技術的にはYaRNと継続事前学習(continued pretraining)を組み合わせてβ版の64Kから拡張したとされています。
ただしPFN自身も、超長文(long-context)の推論は弱点領域として認めています。256Kを「入れられる」ことと「すべてを正確に推論できる」ことは別なので、長文タスクでは精度の検証を前提にすべきです。
日本語トークナイザーのコスト効率
PLaMoは日本語に最適化されたトークナイザーを持ち、日本語1文字あたり約0.54トークン(1トークンあたり約1.85文字)で処理します。同じ日本語テキストでも消費トークンが海外モデル比で約45〜55%少ないとされ、トークン単価×消費量の両面でコストを抑えやすい設計です。日本語中心の業務で使うほど効いてくる特徴です。
出典: Preferred Networks 公式プレスリリース
Reasoning / Non-reasoning 2系統の使い分け
PLaMo 3.0 Primeは、じっくり考える「Reasoning(推論)モデル」と、速く返す「Non-reasoning(高速応答)モデル」を用途で切り替えて使います。 Reasoningを内蔵した国産フルスクラッチモデルとしては先行する存在です。
項目 | Reasoningモデル | Non-reasoningモデル |
|---|---|---|
得意なこと | 複数条件の整理、段階的な結論導出、数理・アルゴリズム、専門QA、意思決定支援 | 要約、定型問い合わせ、情報抽出、分類、チャットボット |
応答速度 | 遅い(長考するため) | 速い |
トークン消費 | 多い | 少ない |
向くシーン | 精度が最優先のタスク | 大量処理・リアルタイム応答 |
切り替えはAPIのreasoning_effortパラメータで制御します。受け付ける値はnone(デフォルト)とmediumの2値のみで、highやlowを渡すと422エラーになります(第三者検証)。
実務で最も注意したいのが、Reasoning有効化によるコスト・速度への影響です。第三者検証では、タスクによってレイテンシが約6〜17倍、トークン消費が約12〜35倍に増えたとの報告があります。さらに推論(長考)部分のトークンはcompletion_tokensに合算されて内訳が見えづらく、コストの見通しを立てにくいという指摘もあります。
つまり「とりあえず常にReasoning」は危険で、本当に段階的推論が必要なタスクに絞って有効化し、大量処理や定型タスクはNon-reasoningで回す、という使い分けが現実的です。
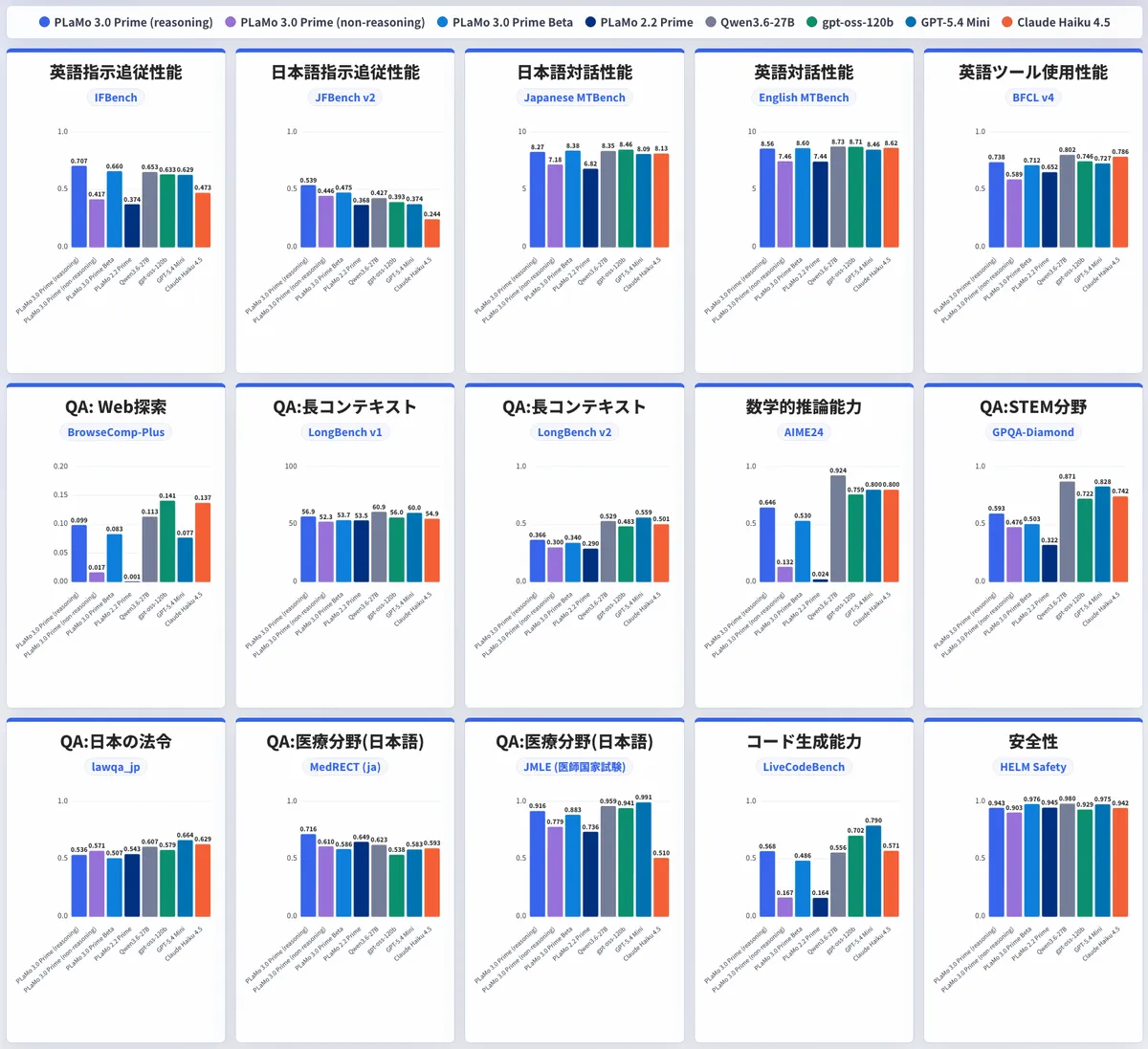
PLaMo 3.0 Primeの強み
最大の強みは「日本語性能×コスト効率×データガバナンス」を一台で満たせることです。 海外モデルにはない国産ならではの利点を整理します。
- 純国産フルスクラッチ: 設計から学習まで自社開発。技術主権・サプライチェーンの観点で評価しやすい。日本語の指示追従に強い。
- 日本語コスト効率: トークナイザーの効率と公開単価の組み合わせで、日本語処理では他社比でかなり安く運用できるとの試算(第三者記事では約1/4〜1/14という幅のある数値も)。
- オンプレミス運用が可能: 機密情報・個人情報を外部に出さない閉域運用ができ、官公庁・金融・医療など規制業種の要件に合わせやすい。
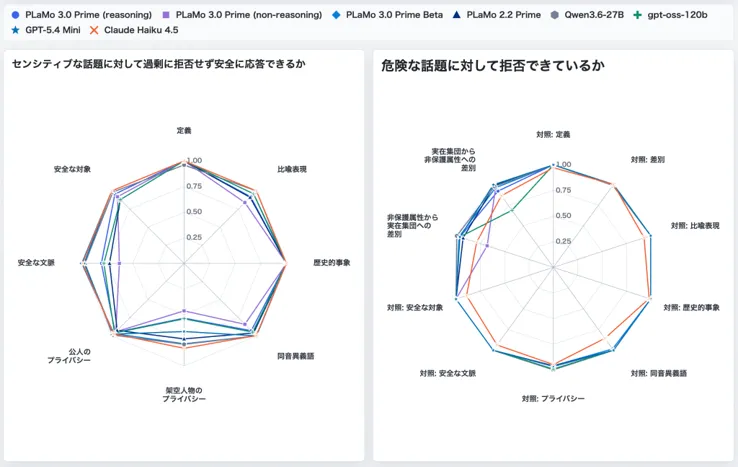
- 安全性への配慮: HELM Safetyベンチマークで海外モデルと同程度以上の安全性能を達成したと公式が説明。NICT提供の安全性データで危険・センシティブ情報への対応を強化。
- 医療・法律ドメインの相対的な強さ: 医師国家試験やMedRECT、法律QA系の評価で上位の競争力をPFNが主張(ただし絶対スコアは公式図表中心で、ここでは相対表現にとどめます)。
- OpenAI互換で導入が軽い: 既存のOpenAI SDKやClaude Code Routerなどとそのまま連携でき、移行コストが低い。
特に「日本語を大量に扱い、かつデータを外に出せない」という日本企業特有の事情に、よく噛み合うモデルだと言えます。国産LLM全体の動向は日本のAI基盤モデル開発の動きやNTT tsuzumi 2の解説も合わせて見ると位置づけが掴みやすくなります。
出典: Preferred Networks 公式プレスリリース
PLaMo 3.0 Primeの弱み・できないこと
強みの裏返しとして、英語タスクや最先端の推論性能、超長文・STEM数学などでは海外フロンティアモデルに及ばない場面があります。 PFN自身も一部を弱点として認めています。導入前に把握しておきたい制約を挙げます。
- Reasoning有効時のコスト増・遅延: 第三者検証ではレイテンシ約6〜17倍、トークン消費約12〜35倍との報告。コスト透明性にも課題。
- 最大出力トークンの上限: 1リクエストあたり約2万トークンが上限との第三者検証。長大な出力を一括で得たい用途では分割が必要。
- 弱点領域: Web検索、超長文(long-context)推論、STEM数学、日本語法律ドメインの一部タスク。
- 英語・最先端推論: 英語タスクやフロンティアの推論性能では海外モデルが依然優位(PFNも言及)。
- 本体はクローズド: Primeの重みは非公開。完全ローカル運用したい場合はbaseモデルかオンプレ契約が前提。
- 認証要件は要確認: 第三者記事ではリリース時点でSOC2 / ISMAP認証は未取得との指摘あり。金融・官公庁の本番調達では認証要件を満たさない可能性があり、最新の取得状況を公式に確認すべき(本記事執筆時点では未確認)。
弱点を踏まえると、「英語中心の高度な推論をフロンティア品質で回したい」用途には現時点では不向きで、その場合は海外モデルと併用する設計が無難です。
PLaMo 3.0 Primeの料金・プラン
PLaMo APIの料金プランは Free / Standard / Provider の3種類で、Standardは入力¥60・出力¥250(いずれも1Mトークンあたり)の従量課金です。 無料で試せるFreeプランがある点が大きな魅力です。
プラン | 対象 | 価格 |
|---|---|---|
Free(無料) | まず試したい人。利用量などに制限あり | 無料(制限付き) |
Standard | 一般的なAPI利用。最大128Kコンテキストまで | 入力 ¥60 / 1Mトークン、出力 ¥250 / 1Mトークン |
Provider | AIサービス提供者・大規模利用向け。カスタマイズ可 | 個別見積もり |
さらに、GAリリースを記念したキャンペーンとして、2026年7月31日までに新規登録すると1,000万トークン相当のクレジットが付与されます(複数の信頼ソースで一致)。検証目的であれば、このクレジットだけでもかなりの量を試せます。
料金面で2点、注意があります。
- 256Kフル利用時の料金区分は要確認: Standardの公開単価は「128Kコンテキストまで」を対象とする旨の記載があります。256Kフルコンテキストを使う場合の課金区分は本記事執筆時点で未確認のため、公式料金ページ/ヘルプセンターで最新情報を確認してください。
- Reasoningのコストは読みにくい: 推論トークンが出力トークンに合算されるため、Reasoningを多用すると想定以上に費用が膨らむことがあります。
実際の課金は入力/出力トークンの従量制です。最新の単価・プラン詳細は必ずPLaMo API公式とヘルプセンターで確認してください。
PLaMo 3.0 Primeの使い方(API・モデルID・reasoning_effort)
PLaMo APIはOpenAI互換なので、エンドポイントとAPIキー、モデルID plamo-3.0-prime を指定すれば既存のOpenAIクライアントでそのまま呼び出せます。 大まかな手順は次の通りです。
- PLaMoのアカウントを登録(GAキャンペーン期間中はクレジット付与あり)
- 管理画面でAPIキーを発行
- OpenAI互換エンドポイント(例:
https://api.platform.preferredai.jp/v1)を指定 - モデルID
plamo-3.0-primeを指定してリクエスト - 必要に応じて
reasoning_effortでReasoningを切り替え
OpenAI Python SDKを使う場合のイメージ:
from openai import OpenAI
client = OpenAI(
base_url="https://api.platform.preferredai.jp/v1",
api_key="YOUR_PLAMO_API_KEY",
)
# 高速応答(Non-reasoning, デフォルト)
res = client.chat.completions.create(
model="plamo-3.0-prime",
messages=[{"role": "user", "content": "この契約書の要点を3つにまとめて"}],
reasoning_effort="none", # デフォルト
)
# 段階的に考えさせたいとき(Reasoning)
res = client.chat.completions.create(
model="plamo-3.0-prime",
messages=[{"role": "user", "content": "複数の制約を満たすシフト表を作って"}],
reasoning_effort="medium", # none か medium の2値のみ
)ポイントはreasoning_effortがnone(デフォルト)かmediumの2値のみであること。highやlowを渡すと422エラーになります。Tool calling(関数呼び出し)や構造化出力もOpenAIフォーマットの標準パラメータで動作するため、既存のエージェント実装やワークフローへ組み込みやすいのが利点です。
なお、コードを書かずに試したい場合はWebチャットの「PLaMo Chat」から触れます。まず動作を体感し、本格的に組み込む段階でAPIに移行する流れが分かりやすいでしょう。
出典: Preferred Networks Tech Blog
他モデルとの違い(海外フロンティアモデル・他の国産LLM)
PLaMo 3.0 Primeは「日本語効率・コスト・データガバナンス」で選ぶモデルで、英語の最先端推論性能で海外モデルと真っ向勝負するモデルではありません。 比較の観点を整理します。
比較ポイント | PLaMo 3.0 Prime | 海外フロンティアモデル(GPT/Claude/Gemini系) |
|---|---|---|
開発主体 | 日本(PFN)・フルスクラッチ | 海外ベンダー |
日本語トークン効率 | 高い(約1.85文字/トークン) | 相対的に低い |
コンテキスト長 | 256K | モデルにより数十K〜数百K以上 |
Reasoning | あり(none/medium) | モデルにより多段階 |
英語・最先端推論 | 海外勢が優位 | 強い |
オンプレ・閉域運用 | 可能(契約) | 限定的・条件付き |
データ主権 | 国産で訴求しやすい | 海外法域の影響を受けうる |
PFNの主張では、同価格帯の海外モデルやオープンモデル(Qwen系など)と比べて、日本語の指示追従とコーディングで競争力があるとされています。海外オープンモデルの代表格であるQwenの最新モデルと比較検討すると、コスト効率・日本語性能・運用形態のトレードオフが見えてきます。
国内に目を向けると、政府の生成AI利用環境「源内(GENNAI)」の基盤モデルとして採用されたNTTのtsuzumi 2など、日本語特化LLMの選択肢は増えています。PLaMo 3.0 Primeもこの源内で試用される国内LLMの一つに選定されています。
実務上の選び分けの目安は次の通りです。
- 日本語中心・コスト重視・データを外に出せない → PLaMo 3.0 Prime
- 英語中心・最先端の高度推論が必須 → 海外フロンティアモデル
- 完全ローカルで重みを自前運用したい → PLaMoのbaseモデルや他のオープンモデル
なお、本記事で触れた海外モデルの価格・性能は変動が速いため、比較する際は各社公式の現行情報を別途確認してください。
デジタル庁「源内」採用と国内での広がり
PLaMo 3.0 Primeは、デジタル庁が整備する政府共通の生成AI利用環境「源内(GENNAI)」で試用される国内LLMの一つに選定されています。 国産・オンプレ運用可能という性格が、機密性の高い行政利用と相性が良いためです。
源内は政府職員向けの生成AI基盤で、複数の国内LLMを切り替えて使える設計になっています。第三者記事では「2026年5月から39機関・約18万人規模の実証が進行中」といった数値も紹介されていますが、規模・期間の具体的数値は公式リリースでの裏取りが取れていないため、参考値として扱ってください。源内そのものの仕組みはガバメントAI「源内」の解説で詳しく整理しています。
このほか、第三者記事では自治体・教育機関・SaaSへの組み込み、金融特化モデルへの横展開などの事例も紹介されています。ただし具体的な機関名・規模は公式での確認が取れていないため、本記事では「広がりつつある」という現状認識にとどめます。
PLaMo 3.0 Primeが向いている企業・向いていない企業
「日本語を大量に扱い、データを外に出せず、コストを抑えたい」企業ほどPLaMo 3.0 Primeの恩恵が大きく、英語中心で最先端推論を求める用途には現時点では不向きです。
こんな企業・用途におすすめ
- 日本語の社内文書・問い合わせ・要約を大量に処理し、コストを抑えたい
- 官公庁・金融・医療など、機密情報を閉域(オンプレ)で扱う必要がある
- データ主権・国産であることを重視する(調達要件・社内方針)
- 既存のOpenAI互換実装に、低コストな日本語モデルを追加したい
- 無料プランやクレジットでまず効果検証してから本番導入したい
おすすめしない・要検討の企業・用途
- 英語タスクや最先端の高度推論をフロンティア品質で回したい
- Web検索連携やSTEM数学、超長文推論が中心
- SOC2 / ISMAPなどの認証取得を本番調達の必須要件にしている(最新の取得状況を要確認)
- Reasoningを多用する設計で、コスト・レイテンシの上振れを許容できない
- 重みを完全ローカルで自前運用したい(その場合はbaseモデルかオンプレ契約を検討)
導入を判断する際は、まずFreeプランやGAキャンペーンのクレジットで自社の代表的なタスクを試し、Non-reasoning中心で十分な精度・速度が出るかを確認するのが堅実です。そのうえで、機密度・言語・コスト・認証要件の4点で本番採用可否を見極めると判断を誤りにくくなります。
よくある質問(FAQ)
Q. PLaMo 3.0 Primeは無料で使えますか?
A. Freeプラン(制限付き)があり、無料でAPIを試せます。加えて2026年7月31日までの新規登録で1,000万トークン相当のクレジットが付与されるGAキャンペーンが告知されています。本格利用はStandard(従量課金)またはProvider(個別見積もり)です。
Q. 海外モデルのリブランドではないのですか?
A. PLaMo 3.0 Primeはアーキテクチャ・トークナイザー・学習まで自社開発した「フルスクラッチ」の国産モデルとされており、海外モデルをベースにした派生モデルではありません。
Q. ReasoningとNon-reasoningはどう選べばよいですか?
A. 複数条件の整理や段階的な推論が必要なタスクはReasoning(reasoning_effort="medium")、要約・分類・定型応答など速度重視のタスクはNon-reasoning(none)が目安です。Reasoningはコスト・レイテンシが大きく増えるため、必要なタスクに絞るのが実務的です。
Q. 256Kコンテキストはそのまま安く使えますか?
A. Standardの公開単価は「128Kまで」を対象とする旨の記載があり、256Kフル利用時の料金区分は本記事執筆時点で未確認です。公式料金ページとヘルプセンターで最新情報を確認してください。
Q. オンプレミスで使えますか?
A. オンプレミス提供があり、機密情報・個人情報を外部に出さない閉域運用が可能です。官公庁・金融・医療などの要件に合わせやすい点が強みです。
Q. 既存のOpenAI向けコードはそのまま動きますか?
A. OpenAI互換APIのため、エンドポイントとAPIキー、モデルID plamo-3.0-prime を指定すれば既存のOpenAI SDKやツールをほぼそのまま流用できます。Tool callingや構造化出力にも対応します。
まとめ
PLaMo 3.0 Primeは、PFNがフルスクラッチで開発した純国産の生成AI基盤モデルです。256Kコンテキスト、Reasoning/Non-reasoningの2系統、日本語に最適化されたトークナイザーによるコスト効率、そしてオンプレ運用によるデータガバナンスを兼ね備えています。2026年6月22日にGAとなり、無料プランと7月31日までのクレジット付与で検証を始めやすいのも特徴です。
一方で、英語・最先端推論・超長文・STEM数学などは弱点領域で、Reasoning多用時のコスト増やSOC2/ISMAP認証の状況など、本番調達では確認すべき点も残ります。「日本語・コスト・データ主権」を軸に選ぶなら有力な選択肢であり、まずはFreeプランで自社タスクを試し、機密度・言語・コスト・認証要件の4点で採用可否を見極めるのが賢明です。最新の料金・仕様は必ずPLaMo API公式で確認してください。
この記事の著者

AI革命
編集部
AI革命株式会社の編集部です。最新のAI技術動向から実践的な導入事例まで、企業のデジタル変革に役立つ情報をお届けしています。豊富な経験と専門知識を活かし、読者の皆様にとって価値のあるコンテンツを制作しています。
最新記事

Tencent Hy3 Preview(Hunyuan 3.0)とは?元OpenAI姚順雨が率いる295B MoE・21B active・256K中国産フラッグシップを徹底解説
2026/04/18

Sakana Fuguとは?日本発マルチエージェントAIの仕組み・Fugu Ultra・料金・使い方を整理【2026年6月速報】
2026/06/23

Qwen3.6-Plusとは?SWE-bench 78.8%・1Mコンテキストの中位モデルを料金・使い方まで徹底解説
2026/04/26

Sakana Marlinとは?日本発Ultra Deep Research AI・8時間自律調査・料金・ChatGPTとの違いを解説
2026/06/22

Mozilla Thunderboltとは?OSS・セルフホスト型AIクライアントの特徴・料金・使い方を解説
2026/04/24

Gemini 3.5 Live Translateとは?70言語リアルタイム音声翻訳の仕組み・料金・使い方・他AI比較を整理【2026年6月】
2026/06/22
