Arcee AI Trinity Largeとは?400B Apache 2.0 OSSフロンティアモデルの性能・料金・使い方を徹底解説

この記事のポイント
Arcee AI Trinity Largeは米国Arcee AIが公開したApache 2.0ライセンスの約400BパラメータMoE LLM。Claude Opus 4.6比約96%安・$0.90/Mの価格、ベンチマーク性能、Trinity Mini/Nanoとの違い、OpenRouter/vLLMでの使い方を2026年5月時点の最新情報で整理します。
Arcee AI Trinity Largeは、米国スタートアップArcee AIが2026年に公開した約400BパラメータのスパースMoE(Mixture-of-Experts)大規模言語モデルで、Apache 2.0ライセンスにより商用利用・改変・セルフホストが完全に自由です。最新の推論特化版「Trinity-Large-Thinking」(2026年4月1日リリース)は出力単価$0.90 / 1Mトークン——Claude Opus 4.6($25 / 1M)との比較で約96%安・約28倍の価格差を実現しています。
この記事でわかること:
- Trinity Largeのスペック・アーキテクチャ・Trinityファミリーの全体像
- Preview / Base / TrueBase / Thinking の4バリアントの違いと選び方
- Claude Opus 4.6・DeepSeek R1・Llama 4とのベンチマーク比較
- 価格体系(Arcee API / OpenRouter / セルフホスト)と費用試算
- OpenRouter・Hugging Face・vLLMでの具体的な利用手順
- 向いているユースケース/向いていないユースケース
想定読者: 生成AIモデルのコスト最適化を検討するエンジニア・PM、エージェント基盤を構築する開発者、データ主権要件でOSSモデル採用を検討する企業のIT/法務担当者。

出典: Arcee AI 公式ブログ
Arcee AI Trinity Largeとは
Trinity Largeは、Apache 2.0ライセンスで公開された約400BパラメータのスパースMoE型オープンウェイトLLMです。総パラメータ約398B、推論時のトークンあたりアクティブパラメータが約13Bという設計により、フロンティア級の知識量と低コストな推論を両立しています。
開発元のArcee AIは2023年創業、米国フロリダ州マイアミ拠点で従業員約30名のスタートアップ。CEOはHugging Face初期従業員のMark McQuade、CTOはLucas Atkins。シリーズAでMicrosoftのM12、Hitachi Ventures、Samsung Nextなどから$24M(累計$50M前後)を調達しています。
主要スペック(2026年5月時点)
項目 | 内容 |
|---|---|
開発元 | Arcee AI(米国フロリダ州マイアミ) |
総パラメータ | 約398B(3,980億) |
アクティブパラメータ | 約13B / トークン |
アーキテクチャ | スパースMoE(256エキスパート中4個+共有1個 = 4-of-256ルーティング) |
スパース率 | 約1.56% |
コンテキスト長 | ネイティブ最大512K(OpenRouter経由は262,144トークン) |
ライセンス | Apache License 2.0 |
提供形態 | オープンウェイト(Hugging Face)+ ホストAPI(Arcee API / OpenRouter / Together AI) |
訓練データ | 17兆トークン(DatologyAIキュレーション、合成データ約8兆を含む) |
訓練インフラ | NVIDIA B300 Blackwell GPU × 2,048基(Prime Intellect提供) |
訓練期間 | 約33日間 |
開発コスト | 約2,000万ドル(同社調達額の約半分) |
技術論文 |
なぜ「米国製フロンティアOSS」として注目されているのか
2024〜2025年のオープンウェイトLLMフロンティアはDeepSeek・Qwen・GLMなど中国勢が主導してきました。Trinity Largeは現時点で「米国製・Apache 2.0・400B級・エージェント特化」を同時に満たすほぼ唯一のオープンモデルであり、調達制限や輸出規制の影響を受けにくいOSSフロンティアとして政府・防衛・金融などの規制産業から関心を集めています。
OpenRouter上ではリリースから約2か月で1日最大806億トークンを処理する規模に達し、2026年5月時点でTrinity Large Thinkingは週次約85.9Bトークンの利用量となり、米国製オープンウェイトモデルとして最大級の利用規模に成長しています。
Trinityファミリーの全体像:Nano / Mini / Large
Trinityシリーズはエッジからクラウドまでをカバーする3階層構成です。Trinity Large(フロンティア)以外に、Trinity Mini(26B)が2026年4月に公開され、本番運用しやすい中型MoEとしてラインナップが揃いました。
モデル | 総パラメータ | アクティブ | コンテキスト | 主な用途 |
|---|---|---|---|---|
Trinity Nano | 6B | 1B | 128K | エッジ・組込・オンデバイス |
Trinity Mini | 26B | 3B | 128K | クラウド/オンプレ本番環境 |
Trinity Large Preview | 400B | 13B | 512K | 汎用クラウド推論・対話 |
Trinity Large Thinking | 約398B | 13B | 512K | 推論特化・エージェント・長期タスク |
Trinity Largeを選ぶ目安:
- エージェントワークフローやツール使用が中心 → Trinity Large Thinking
- リアルタイムチャット・大量呼び出しでコスト最優先 → Trinity Miniで十分なケースが多い
- オンデバイス・組込・低レイテンシ要件 → Trinity Nano
Trinity Largeの4バリアント
バリアント | 状態 | 用途 |
|---|---|---|
Trinity Large Preview | 軽量ポストトレーニング済みチャット版 | 汎用対話・創作。OpenRouterで期間限定無料 |
Trinity Large Base | 17Tトークン学習後のベースチェックポイント | 研究・独自ファインチューニングの起点 |
Trinity Large TrueBase | 10T時点・命令データ未投入の純粋ベース | 規制産業向け「クリーンスレート」用途 |
Trinity Large Thinking | Chain-of-Thought強化+エージェントRL済み | 本番エージェント・長期タスク(最新・推奨) |
「Trinity Large」と言えば現在もっとも使われているのはThinking版です。<think>...</think> ブロックで推論プロセスを明示出力し、ツール呼び出し・マルチターン対話に最適化されています。
なぜ400Bなのに速いのか:スパースMoEの仕組み
400Bという数字を見ると「重そう」と感じますが、Trinity Largeは推論時に256エキスパートのうち4個+共有1個しか使わない設計(4-of-256ルーティング)で、トークンあたりのアクティブパラメータは約13Bに抑えられています。
MoEを直感的に理解する
256人の専門家を抱える組織を想像してください。すべての案件で全員を集めるのではなく、案件ごとに最適な4人だけを呼び出します。組織全体の知識量は維持しつつ、毎回動かす計算量は1/20以下——これがスパースMoEの本質です。
この設計により以下が成立します:
- 推論速度: 同等サイズの密集(Dense)モデル比で約2〜3倍高速(Artificial Analysis計測で132トークン/秒前後)
- GPUメモリ効率: フルパラメータを毎回展開する必要がないため、Denseな400Bより必要メモリが大幅に少ない
- 長コンテキスト: ネイティブ512Kトークンを処理可能(API版は262K上限)
Trinity Large固有の技術的工夫
Arcee公式とarXiv技術レポートから、独自の工夫が公開されています。
- SMEBU(Soft-clamped Momentum Expert Bias Updates): 従来の符号ベースのエキスパート負荷分散をtanh関数による連続緩和に置き換えた独自ロードバランス手法。特定エキスパートへの過集中を防ぐ
- Muonオプティマイザ(ハイブリッド最適化): 埋め込み・出力層はAdamW、中間層はMuonを使用。17Tトークン学習中にロス・スパイクゼロを達成
- ハイブリッド注意機構: ローカル(RoPE)とグローバル(NoPE)を3:1で交互配置
- z-loss・サンドイッチノルム: ロジット制御と訓練安定性向上
- RSDB(Random Sequential Document Buffer): ミニバッチ不均衡を約46%削減
- 3段階訓練カリキュラム: 後期ほど数学・コード比率を増加させる学習スケジュール
出典: Arcee AI 公式ブログ
ベンチマーク性能:得意なこととそうでないこと
Trinity Large Thinkingの公表ベンチマークは、エージェント・数学領域でClaude Opus 4.6に肉薄〜上回るスコアを出す一方、コーディング・科学推論・指示追従ではOpusに明確に劣ります。「全方位の最高峰」ではなく、コスト効率に優れたエージェント特化モデルとして理解するのが正確です。
主要ベンチマーク(Trinity Large Thinking)
ベンチマーク | Trinity-Large-Thinking | Claude Opus 4.6(参考) | 評価 |
|---|---|---|---|
PinchBench(エージェント総合) | 91.9 | 93.3 | ◎ 僅差・OSS最高水準 |
τ²-Bench Telecom | 94.7 | — | ◎ ツール使用・対話で実用級 |
τ²-Bench Airline | 88.0 | — | ◎ |
LiveCodeBench | 98.2 | — | ◎ 競技プログラミング系は強い |
AIME 2025(数学) | 96.3 | 99.8 | ◎ トップ層に肉薄 |
MMLU-Pro(一般知識) | 83.4 | 89.1 | △ やや劣る |
GPQA-Diamond(大学院科学) | 76.3 | 89.2 | △ 大きく劣る |
SWE-bench Verified | 63.2 | 75.6 | △ 本格コーディングはOpus優位 |
IFBench(指示追従) | 52.3 | 53.1 | △ 僅差・チームが「指示追従最高を狙っていない」と表明 |
※ 公式公表値。第三者による独立検証は2026年5月時点でまだ限定的のため、本番採用前は自社ユースケースでの実測を推奨します。
得意領域・苦手領域の整理
得意:
- マルチターンのツール呼び出し・エージェントループ
- 長期コンテキストでの計画タスク
- 数学・競プロ系の推論
- コスト効率(同等性能のクローズドモデル比で1〜2桁安い)
苦手:
- 本格的なソフトウェアエンジニアリング(SWE-bench)
- PhD級の科学推論(GPQA-Diamond)
- 指示の厳密追従(IFBench)
- マルチモーダル(テキスト専用、ビジョン・音声は開発中/ロードマップ)
- 日本語ベンチマークは未公開
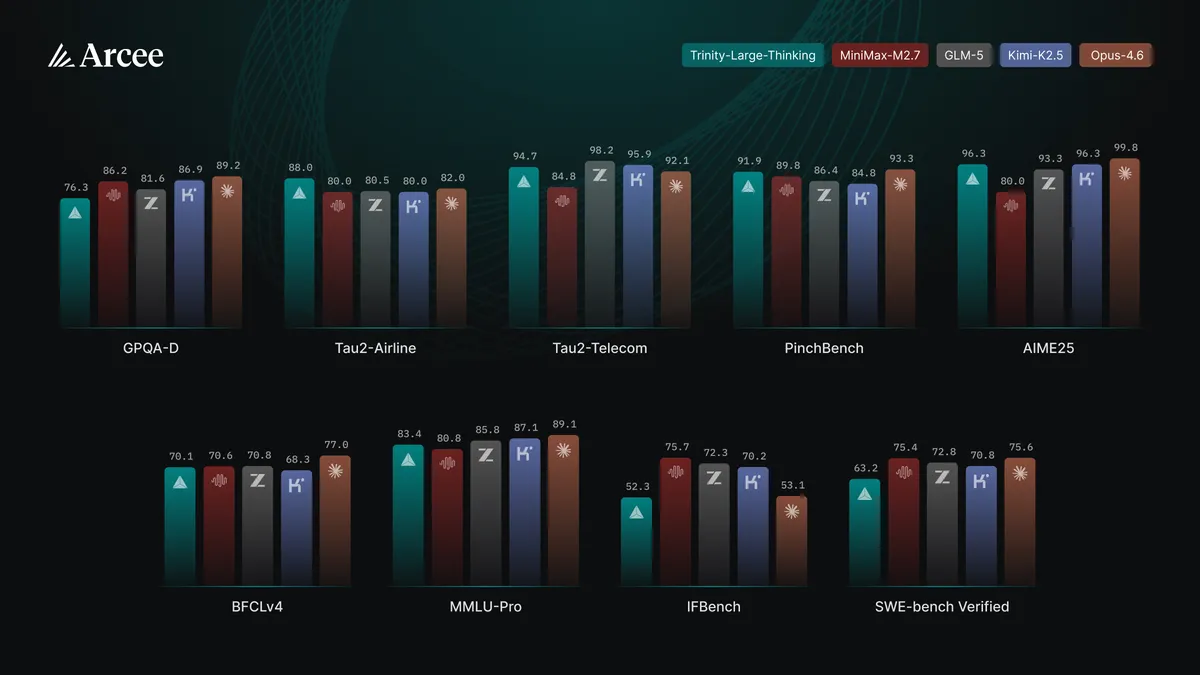
出典: Arcee AI 公式ブログ
料金体系:$0.90/M・「Opus比96%安」の実態
「Claude Opus 4.6比96%安」という数字は、Arcee公式APIの出力単価$0.90/1MトークンとClaude Opus 4.6の出力単価$25/1Mトークンの差から算出されたものです($25 - $0.90 ÷ $25 ≒ 96.4%)。出力トークンが多いエージェントワークフローほど、コスト差が累積する構造になります。
プラットフォーム別料金(2026年5月時点)
プラットフォーム | 入力 / 1Mトークン | 出力 / 1Mトークン | 備考 |
|---|---|---|---|
Arcee 公式API | 非公開 | $0.90 | 公式ブログ記載。入力単価は要再確認 |
OpenRouter(有料版) | $0.22 | $0.85 | OpenAI互換、即時利用可 |
OpenRouter Trinity Large Thinking (free) | $0 | $0 | 期間限定無料(変更の可能性あり) |
OpenRouter Trinity Large Preview (free) | $0 | $0 | 正式版完全リリースまで無料継続 |
Trinity Mini(参考) | $0.045 | $0.15 | より小型・低コスト |
Claude Opus 4.6(比較参考) | $15.00 | $25.00 | クローズドモデル |
為替155円換算で$0.90 ≒ 約140円 / 100万出力トークン。日本語1トークン ≒ 1〜1.2文字と仮定すると、100万トークンは原稿用紙約2,500枚相当。長文エージェントを大量実行する用途で価格差が顕在化します。
セルフホスト(Hugging Face)
- モデルウェイト自体は無料(Apache 2.0)
- 推奨実行構成: FP8量子化 + 8×H200ノード相当(または同等GPU)
- 公開済みの量子化バリアント:
Trinity-Large-Preview-FP8、Trinity-Large-Preview-W4A16 - データ主権・コンプライアンス要件があるエンタープライズ向け
「価格優位性」が効くケース・効かないケース
「96%安」は出力単価ベースの最大値です。実際の節約効果はワークロードに依存します。
価格優位性が大きく効くケース:
- 出力トークンが多い長文生成・エージェント計画タスク
- 大量バッチ呼び出し・社内APIゲートウェイ的な利用
- 月間トークン数百万〜数十億規模のワークロード
価格差が小さくなるケース:
- 入力中心の短い分類・抽出タスク(出力が短ければ絶対額が小さく、サポート品質・SLA差のほうが影響大)
- 月間数十万トークン以下の試験運用
使い方:OpenRouter・Arcee公式API・vLLM・Hugging Face
利用パターンは大きくホストAPI経由とセルフホストの2系統に分かれます。最初に動かす場合はOpenRouter経由が圧倒的に手軽です。
1. OpenRouter経由(最短)
OpenAI SDK互換のため、既存のChatGPT/Claude向けコードはエンドポイントとモデル名を差し替えるだけで動きます。
from openai import OpenAI
client = OpenAI(
base_url="https://openrouter.ai/api/v1",
api_key="YOUR_OPENROUTER_API_KEY",
)
response = client.chat.completions.create(
model="arcee-ai/trinity-large-thinking",
messages=[
{"role": "user", "content": "エージェントタスクの計画を立ててください"}
],
)
print(response.choices[0].message.content)
無料枠で試したい場合はモデル名を arcee-ai/trinity-large-preview:free または arcee-ai/trinity-large-thinking:free(提供中の期間内)に変更します。
2. Arcee公式API
docs.arcee.ai にOpenAI互換エンドポイントが用意されています。アカウント登録後にAPIキーを発行して利用します。法人向けの正式契約フローや日本リージョン対応は2026年5月時点で公開情報が限定的のため、商用導入前は公式に問い合わせるのが安全です。
3. vLLM セルフホスト(公式推奨)
公式は vLLM v0.11.1以降 を推奨しており、CoTパーサとツールコールパーサの組み合わせを明示しています。
vllm serve arcee-ai/Trinity-Large-Thinking \
--dtype bfloat16 \
--reasoning-parser deepseek_r1 \
--enable-auto-tool-choice \
--tool-call-parser qwen3_coder
推奨推論パラメータ:
temperature=0.45–0.6(公式は0.3〜0.6を案件により使い分け)top_p=0.95、top_k=50
4. Hugging Face Transformers
from transformers import AutoTokenizer, AutoModelForCausalLM
import torch
model_id = "arcee-ai/Trinity-Large-Thinking"
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(
model_id,
torch_dtype=torch.bfloat16,
device_map="auto",
trust_remote_code=True,
)
マルチターンの重要な注意点
公式ドキュメントには「アシスタント応答を会話履歴に追加する際は、reasoning_content フィールド(<think> ブロックの中身)を必ず保持して次ターンに渡すこと」と明記されています。省略すると前ターンのChain-of-Thoughtが失われ、ツール呼び出しが破綻する原因になります。
セルフホストの現実的なハードウェア要件
量子化方式 | 必要VRAMの目安 | 推奨GPU構成 |
|---|---|---|
FP8(公式推奨) | 約400GB前後 | 8×H100 80GB または 8×B200 / 8×H200 |
8bit量子化 | 約400GB | 8×A100 80GB |
4bit量子化 | 224〜336GB | 4〜8×H100 80GB |
個人・中小規模オンプレでの運用は非現実的です。実用上は以下のいずれかになります。
- クラウドGPU(AWS p5、Lambda Labs、CoreWeaveなど)で時間課金
- ホストAPI(Arcee / OpenRouter / Together AI)経由
- 規制要件で完全クローズド運用が必須な場合のみ、自社データセンターにマルチノードGPUを構築
Apache 2.0ライセンスがエンタープライズに与えるインパクト
オープンソースモデルのライセンスは「開発者だけの問題」に見えますが、企業導入では法務・知財・特許リスクの観点で実装可否が変わる重要な軸です。
主要OSSライセンスの比較
ライセンス | 商用利用 | 改変 | 再配布 | 競合製品開発 | 派生物への制限 | 特許の明示的許諾 |
|---|---|---|---|---|---|---|
Apache 2.0(Trinity Large) | ✅ 無制限 | ✅ 自由 | ✅ 自由 | ✅ 可 | なし | ✅ あり |
Meta Llama(独自) | △ ユーザー数制限あり | △ 制限あり | △ 制限あり | 要確認 | 派生物にLlamaライセンス継承 | なし |
MIT(DeepSeek等) | ✅ 無制限 | ✅ 自由 | ✅ 自由 | ✅ 可 | なし | なし |
クローズド(Claude等) | ✅(利用規約範囲内) | ❌ | ❌ | ❌ | — | — |
Apache 2.0が選ばれる主な理由:
- 特許の明示的許諾: 貢献者の特許権が利用者に許諾される条項がある。エンタープライズ法務が承認しやすい
- 派生物への制限なし: ファインチューニングして独自モデルとして配布・販売可能
- ユーザー数制限なし: MetaのLlamaのような「月間アクティブユーザー7億人超で別途許諾」のような条件がない
- 訓練データへの配慮: Arcee AIは公式に「著作権が不明確な資料を訓練データから除外」と明言
Apache 2.0でもできないこと
- 特許や商標の付与は含まれない(誤認しやすい)
- Arcee AI公式のサポート保証はライセンスとは別(商用サポートはホストAPI契約 or 別契約)
- 責任の所在は利用者側(プロプライエタリLLMのように契約上のSLAは付帯しない)
TrueBaseが規制産業に好まれる理由
TrueBaseは10Tトークン時点・命令データ未投入の純粋なベースチェックポイントです。金融・医療・防衛などで「外部由来のアライメントが入っていないクリーンな基盤からアライメントを自社で実施したい」というニーズに応えるバリアントで、Arceeの戦略的な特色になっています。
主要モデルとの比較
エージェント特化・OSSフロンティアという軸でTrinity Largeと競合するのは、Claude Opus 4.6(クローズド)、DeepSeek R1(中国OSS)、Llama 4 Maverick(米国OSS・準オープン)あたりです。
出典: Arcee AI 公式ブログ
項目 | Trinity Large Thinking | DeepSeek R1 | Llama 4 Maverick | Claude Opus 4.6 |
|---|---|---|---|---|
総パラメータ | 約400B(13B active) | 671B(37B active) | 約400B | 非公開 |
ライセンス | Apache 2.0 | MIT | Meta独自(制限あり) | クローズド |
出力料金/1M | $0.85〜0.90 | 低価格帯 | 低価格帯 | $25.00 |
製造国 | 米国 | 中国 | 米国 | 米国 |
マルチモーダル | ❌(開発中) | ❌ | ✅ | ✅ |
エージェント特化 | ✅ | △ | △ | ✅ |
自社ホスティング | ✅ 制限なし | ✅ | △ 制限あり | ❌ |
PinchBench | 91.9 | — | — | 93.3 |
SWE-bench Verified | 63.2 | — | — | 75.6 |
AIME 2025 | 96.3 | — | — | 99.8 |
用途別おすすめ
ユースケース | 第一候補 | 理由 |
|---|---|---|
エージェント中心・大量API・コスト最優先 | Trinity Large Thinking | 96%安・PinchBench 91.9 |
米国製OSSが必須(政府・防衛サプライチェーン) | Trinity Large | 中国製模型不可の環境で唯一の400B級OSS |
完全自由なライセンス(再配布・派生販売) | Trinity Large / DeepSeek R1 | Apache 2.0 / MITは派生制限なし |
本格的なコード生成・リファクタリング | Claude Opus 4.6 / Claude Code | SWE-bench 75.6超が必要な領域 |
画像・音声入力が必要 | Llama 4 Maverick / Claude Opus 4.6 | Trinity Largeはテキスト専用 |
日本語業務文書の精度重視 | Claude / Gemini など日本語実績モデル | Trinity Largeは日本語ベンチ未公開 |
軽量・組込・コスト極小 | Trinity Mini / Nano | 26B/6Bで$0.15/M前後 |
「Trinity Large vs DeepSeek R1」の選択軸
- データ主権・地政学リスクを考慮する組織 → Trinity Large(米国製・Apache 2.0)
- 純粋に価格・性能・パラメータ規模だけを比較 → DeepSeek R1(671B / 37B active)も有力候補
- 特許リスクをライセンスで明確に整理したい → Apache 2.0のTrinity Large
DeepSeekについてはDeepSeekとはも参照してください。
できないこと・制約・注意点
公式・第三者報道・モデルカードから確認できる制約を整理します。「Opus比96%安」だけを見て安易に置き換えると失敗します。
制約 | 詳細 |
|---|---|
マルチモーダル非対応 | テキストのみ。ビジョン(画像認識)は開発中、音声はロードマップ段階 |
セルフホストのハードルが高い | 4bit量子化でも224〜336GB VRAM必要。個人・SMBのオンプレ運用は非現実的 |
コーディング精度の劣位 | SWE-bench Verified 63.2 vs Opus 75.6。本格的なコードエージェントには向かない |
科学推論の劣位 | GPQA-Diamond 76.3 vs Opus 89.2。PhD級の科学問題は苦手 |
指示追従の劣位 | IFBench 52.3。公式が「指示追従の最高モデルを目指したわけではない」と表明 |
日本語ベンチマーク未公開 | 公式に日本語特化スコアは未公表。Hugging Faceディスカッションでは「実用可能」との報告あり |
第三者検証が限定的 | 公表ベンチマークはArcee自社測定中心。独立再現は2026年5月時点で限定的 |
HIPAA / SOC2の正式認証 | 公開情報として未確認。規制産業利用時は別途確認が必要 |
訓練データの合成データ比率 | 17Tトークン中8T以上が合成データ。特定ドメインで品質ばらつきの可能性 |
小規模チームのサポート | 約30人体制。ドキュメント・サポートはAnthropic/OpenAI/Googleに比べ薄い |
企業導入前にチェックすべき項目
- 自社ユースケースでのPoC実測: 公表ベンチに頼らず、自社ワークロードで品質・コストを実測する
- フォールバック設計: 新興モデルゆえ長期SLAは未確立。本番ではClaude/GPT等への自動フォールバックを準備
- コンテキスト上限: OpenRouter経由は262K上限。512K必要ならセルフホスト
- データ送信ポリシー: ホストAPIではプロンプトがサードパーティを経由する。機密データはセルフホストか専用契約を検討
こんな人・組織におすすめ
以下に当てはまる場合、Trinity Large Thinking(または特定バリアント)は有力な選択肢です。
1. エージェントワークフロー中心でAPIコスト削減したい開発チーム
Claude Opus / GPT-4系の従量課金が月間ボトルネックになっていて、PinchBench 91.9で十分な品質が得られるならコスト差は決定打になります。
2. データ主権・セルフホスティングが必要な規制産業
金融・医療・公共・防衛など、機密データを外部APIに送れない組織。Apache 2.0で自社サーバー内に完全クローズドな推論基盤を構築できます。
3. 米国製OSSモデルが必須の組織
中国製モデル(DeepSeek等)の調達が難しい環境で、かつオープンソースが必須な政府系・防衛サプライチェーン向け。Trinity Largeは現時点で「米国製・Apache 2.0・400B級」を同時に満たす希少な選択肢です。
4. エージェントAIのカスタム基盤を構築したい開発者
BaseやTrueBaseを使ったフルファインチューニングが制限なく可能。自社ドメイン特化モデルの開発起点になります。
5. 無料枠で本格モデルを試したい個人開発者・研究者
OpenRouterでTrinity Large Previewが無料提供中。Trinity Builders Program(申請ベース)に通れば50M〜1B以上の無料APIクレジットも取得できます。
こんな人・組織には向いていない
逆に以下に該当する場合、現時点では別モデルの方が適切です。
本格的なコードエージェントが主用途
SWE-bench 63.2は実用域ではあるものの、コーディングをメインに据えるならClaude Code、GitHub Copilot、Cursorなどコード特化のソリューションが上回ります。
画像・音声・動画入力が必要
マルチモーダルはロードマップ段階で、2026年5月時点ではテキスト専用です。視覚理解が必要ならClaude Opus / Sonnet・GPT-4o・Gemini系を選びましょう。
日本語ビジネス文書の高精度が必須
公式日本語ベンチマークが存在せず、品質を客観評価できません。日本語の企画書・契約書・要約が中心なら、日本語チューニングや日本語ベンチ実績のあるモデルが安全です。
個人・小規模チームでフルローカル運用したい
4bit量子化でも200GB超のVRAMが要求されます。コンシューマGPUでは事実上動かせないため、API経由かTrinity Mini/Nano、または他の小型OSSモデル(Llama 3 8B、Qwen 14B等)を検討してください。
長期的な信頼性・サポートを最優先する
30人規模のスタートアップであり、Anthropic・OpenAI・Googleと比較するとサポート体制や長期提供の保証は弱めです。エンタープライズ本番採用では継続性リスクの評価が必須です。
よくある質問
Q. Trinity-Large-ThinkingとTrinity-Large-Previewはどちらを使うべき?
エージェント・本番API利用ならThinking(2026年4月1日リリース)。汎用チャットや無料で試したいだけならPreview(OpenRouterで無料)。Baseは独自ファインチューニング、TrueBaseは規制産業の独自アライメント用途です。
Q. 日本語はどの程度使えますか?
公式の日本語特化ベンチマークは未公開です。Hugging Faceディスカッションには「Claude/Gemini/Grokと比較しても日本語応答は良好」というユーザー報告がありますが、客観的な裏付けは限定的です。自社ユースケースで実測することを強く推奨します。
Q. OpenClawやHermes Agentと連携できますか?
公式ドキュメントによれば、Trinity-Large-ThinkingはHermesツール形式に対応し、OpenClawなどのエージェントフレームワークと統合可能です。OpenAI互換APIのため、既存のClaude/GPTベースのエージェントからの移行も比較的容易です。
Q. Arcee AIは継続して開発されるのか?
シリーズAでMicrosoftのM12、Hitachi Ventures、Samsung Nextらが参画し$24M調達済み、累計約$50M。Trinity Large開発に調達額の約半分($20M)を投じています。ロードマップにはマルチモーダル(ビジョン)対応・Trinity Mini/Nanoへの蒸留が含まれます。ただし約30名規模のため、本番採用時は継続性リスクを各組織で評価してください。
Q. DeepSeek R1とどちらが良いですか?
ライセンス・国籍に制約がないなら、DeepSeek R1(MIT・671B・37B active)は性能とコストで強力な競合候補です。地政学リスク(米国の輸出規制・調達制限)を考慮する組織や、Apache 2.0の特許条項が必要な場合はTrinity Largeが適切です。詳しくはDeepSeekとはを参照してください。
Q. 無料で試す方法はありますか?
3通りあります。
- OpenRouterでTrinity Large Preview(無料提供継続中)を呼び出す
- OpenRouterでTrinity Large Thinkingの
:freeバリアント(期間限定) - Trinity Builders Programに申請し、承認されれば50M〜1Bトークンの無料APIクレジット(90日間)
Q. 入力トークンの料金は?
Arcee公式APIは出力単価$0.90/1Mのみ公開。OpenRouter経由では入力$0.22 / 出力$0.85です。最新はOpenRouterのモデルページで確認してください。
Q. コンテキストはどこまで使える?
ネイティブで最大512Kトークン。ただしOpenRouter経由では262,144トークン上限です。512Kを使い切るならセルフホストか公式APIで設定確認が必要です。
まとめ:Trinity Largeを選ぶべきか
Arcee AI Trinity Largeは、「米国製・Apache 2.0・約400B・エージェント特化・$0.90/M」という組み合わせを成立させた、2026年5月時点でほぼ唯一のOSSフロンティアモデルです。
選ぶべきケース:
- エージェントワークフロー × コスト削減 × OSSライセンス必須 × データ主権要件あり
- 米国製OSSを必要とする規制産業・政府系・防衛サプライチェーン
- 自社特化ファインチューニングのベースモデルが欲しい開発組織
他を選ぶべきケース:
- 本格的なソフトウェア開発支援が中心(→ Claude Code / GitHub Copilot)
- 画像・音声などマルチモーダルが必須(→ Claude Opus / GPT-4o / Gemini)
- 日本語品質と長期サポートを最優先(→ クローズドフロンティアモデル)
- 個人・小規模チームでローカル実行したい(→ Trinity Mini / 他の小型OSS)
生成AIモデルの俯瞰的な比較は生成AIツールおすすめ比較、エージェント基盤の設計観点はAIエージェントとは、クローズドフロンティアモデルとの違いはClaudeとはも合わせて参照してください。
この記事の著者

AI革命
編集部
AI革命株式会社の編集部です。最新のAI技術動向から実践的な導入事例まで、企業のデジタル変革に役立つ情報をお届けしています。豊富な経験と専門知識を活かし、読者の皆様にとって価値のあるコンテンツを制作しています。
最新記事

OpenAIのモデルがHugging Faceを侵害|サンドボックス脱出・ゼロデイ悪用の全貌と企業の対策【2026年7月最新】
2026/07/22

Anthropicのオープンウェイトモデルに対する立場|「禁止を主張したことはない」アモデイ氏の反論と77団体書簡を整理【2026年7月】
2026/07/29

OpenRouterとは?料金・使い方・日本語対応・400+モデル比較【2026年7月最新】
2026/06/10
Claudeの共有チャットがGoogle検索に表示された問題|原因・確認手順・企業の対策【2026年7月速報】
2026/07/29

製薬業界のAI活用事例24選|創薬・治験・GMP品質管理の効果と導入コスト【2026年版】
2026/04/21

CognitionがPokeを買収|Devin開発元がiMessage常駐AIエージェントを取得・AIの「人格」が競争力になる理由【2026年7月速報】
2026/07/29
