MiniMax M2.7とは?自己進化型AIモデルの特徴・性能・料金・使い方を解説

この記事のポイント
MiniMax M2.7は中国MiniMaxが公開した自己進化型の最新オープンウェイトAIモデルです。Claude Opus・GPT-5との性能比較、入力$0.30/1Mの料金、使い方、日本企業が導入する際の注意点まで整理します。
MiniMax M2.7は、中国のAIスタートアップ MiniMax(稀宇科技) が2026年3月に公開した最新のテキスト生成AIモデルです。「モデル自身が自らの進化に深く関与した初の公式リリース」 として話題になり、Claude Opus 4.6・GPT-5.4クラスの性能を入力1/50・出力1/60のコストで提供する点で注目を集めています。
この記事では、MiniMax M2.7の定義・できること・強み/弱み・料金・使い方・他モデルとの違いまで、導入判断に必要な情報を公式情報ベースで整理します。
この記事でわかること:
- MiniMax M2.7の基本情報と「自己進化」の正確な意味
- Claude Opus 4.6 / GPT-5.4 / Gemini 3.1との性能・料金比較
- 日本企業が利用する際のデータガバナンス上の注意点
- どんな用途・どんな企業に向いているか

出典: MiniMax 公式ニュース
MiniMax M2.7の結論(3行まとめ)
- 性能: SWE-Pro 56.22%、Terminal Bench 2 で 57.0%、GDPval-AA で ELO 1495。コード生成とエージェント用途でオープンソース最高水準
- 料金: 入力 $0.30 / 出力 $1.20(100万トークンあたり)。Claude Opus 4.6と比較して 入出力ともに数十分の一
- ライセンス: Modified MIT のオープンウェイトとしてHugging Faceで公開。セルフホスティング可
ざっくり「Claude Opus 4.6クラスをオープンソースかつ圧倒的に安く使いたいエンジニア・企業向け」のモデルです。一方で、MiniMaxは中国企業のため、ホスト版APIを機微情報に使う場合はデータガバナンス上の検討が必要です。
MiniMax M2.7とは
MiniMax M2.7は、中国・上海のAIスタートアップ MiniMax(稀宇科技)が2026年3月18日に公式発表し、2026年4月12日頃にHugging Faceでオープンウェイトを公開したスパースMoE(Mixture-of-Experts)構成のLLM です。M2シリーズ(M2 → M2.1 → M2.5 → M2.7)のフラッグシップとして、エージェント用途・コード生成・オフィス生産性 に特化しています。
特徴を一言でいうと、「Claude Opus 4.6やGPT-5.3/5.4に並ぶ性能を、桁違いに安く、オープンウェイトで提供するオープンソース代替」です。
基本プロフィール
項目 | 内容 |
|---|---|
モデル名 | MiniMax M2.7 / MiniMax-M2.7-highspeed(高速版) |
開発元 | MiniMax(稀宇科技、中国・上海) |
公式発表 | 2026年3月18日 |
オープンウェイト公開 | 2026年4月12日頃(Hugging Face) |
アーキテクチャ | Sparse Mixture-of-Experts |
総パラメータ | 約229B(2290億) |
アクティブパラメータ | 10B(推論時にトークンごとに起動) |
コンテキスト長 | 約200K〜205Kトークン |
ライセンス | Modified MIT |
公式サイト |
シリーズの位置づけ(M2 → M2.7)
MiniMaxのテキストモデルは短期間で急速に進化しています。
- M2(2025年後半): 「Claude Sonnetの8%の価格」を謳い、オープンソース化
- M2.1(2026年初頭): 多言語プログラミング強化
- M2.5(2026年2月頃): プログラミング・ツール呼び出し・検索で複数のSOTA達成
- M2.7(2026年3月18日): 自己進化メカニズムを公開、M2.5と同価格を維持
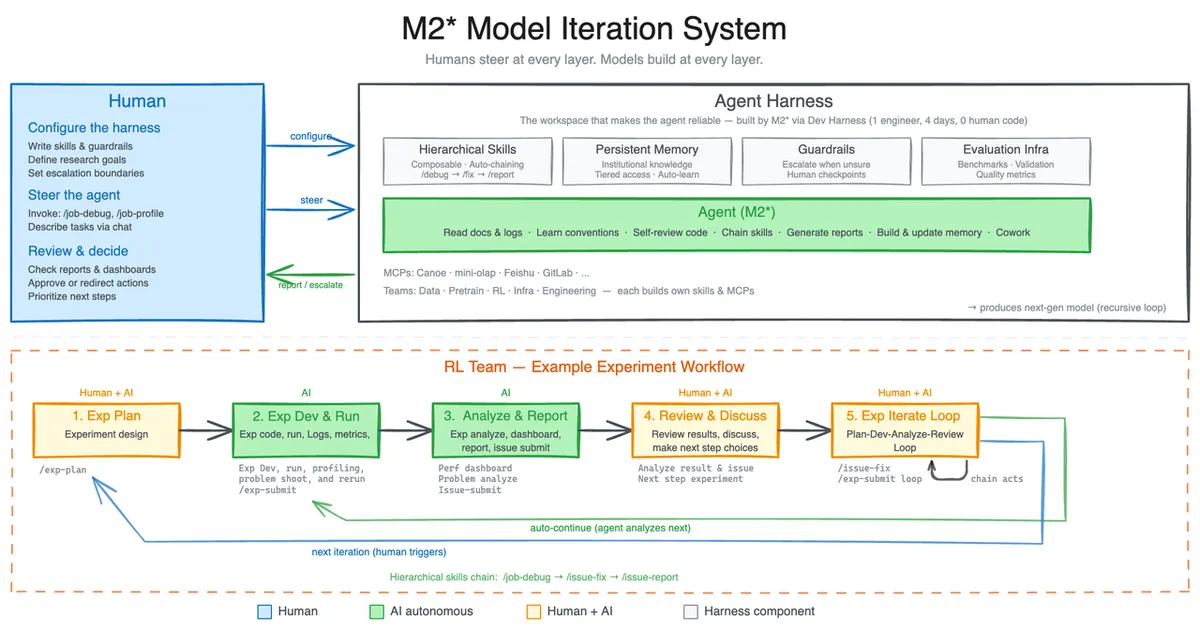
M2.7は「機能追加版」ではなく、モデル自身がスキャフォールド(agent harness)を自動改善する仕組みを内部開発に取り入れた最初のバージョン という位置づけです。
MiniMax M2.7の3つの特徴
MiniMax M2.7が他のオープンソースモデルと違う点は、次の3つに集約できます。
特徴1: 自己進化(Self-Evolving)メカニズム
MiniMax M2.7の最大のトピックは、モデル自身がエージェント用スキャフォールドコードを自律的に改善する仕組み を持つ点です。
具体的には、以下のループを無人で100ラウンド以上回し、内部評価セットで約30%の性能向上を達成したとMiniMaxは説明しています。
- 過去の失敗軌跡を分析する
- 変更計画を立てる
- スキャフォールドコードを書き換える
- 新しいコードで再評価する
- 性能が上がれば採用、下がれば差し戻す
ただし注意点として、ユーザーが触るM2.7本体が常時自己学習し続けるわけではありません。 公開されているのは「M2.7を育てる過程で使われた仕組み」であり、読者や企業が使う際には通常のLLMとして扱います。この点は一部のブログで誤解されやすい部分です。
出典: MiniMax 公式ニュース
特徴2: 入力 $0.30 / 出力 $1.20 の低価格
MiniMax M2.7のもう1つの強みは、公式APIの料金です。M2.5と同価格で据え置き、入力 $0.30 / 100万トークン、出力 $1.20 / 100万トークン で利用できます。
Claude Opus 4.6(入力約$15、出力約$75)と比べると、入力で約1/50、出力で約1/60の水準です。GPT-5.4 Mini(入力$0.75、出力$3.00)と比較しても半額以下で、エージェント用途のように大量トークンを消費するワークロードで特にコストインパクトが大きい モデルです。
特徴3: Modified MITのオープンウェイト
Claude・GPT・Geminiが基本的にプロプライエタリなのに対し、MiniMax M2.7はHugging Faceで重みが公開されており、Modified MITライセンスで配布 されています。
これにより、
- オンプレミス / プライベートクラウドでのセルフホスト が可能
- 自社データでのファインチューニングや推論パイプラインへの組み込みが可能
- ベンダーの障害やポリシー変更に左右されにくい
といった運用が選べます。ただし、「Modified」部分の具体的条項 は利用前に必ずGitHub / Hugging FaceのLICENSEファイルで法務確認することを推奨します。
MiniMax M2.7でできること
MiniMax M2.7は、M2シリーズが狙ってきた 「エージェント・コード・オフィス生産性」 の3領域に強みを持ちます。
コード生成・ソフトウェア開発
- 単発のコードパッチにとどまらず、プロジェクト全体のエンドツーエンド配信 に対応
- マルチ言語対応で、SWE Multilingualで76.5%、SWE-Pro 56.22%
- ターミナル操作を含む開発タスクではTerminal Bench 2で 57.0%(GPT-5.3-Codex相当)
エージェント(ツール使用・自動化)
- 40種類以上の複雑スキル(2000トークン超のスキル仕様書を含む)への遵守率97%
- Shell / Browser / Python実行 / MCPツールとのネイティブ統合
- Agent Teams として、複数エージェントが協働するマルチエージェント構成に対応
オフィス生産性
- Excel / PowerPoint / Word の複雑編集が可能
- GDPval-AA(オフィスドキュメント生産性評価)でELO 1495を記録。オープンソース系最高水準
その他
- Character Consistency による娯楽・ロールプレイ用途での性格一貫性強化
- MCP(Model Context Protocol)経由のツール呼び出しに対応
MiniMax M2.7の性能ベンチマーク
公式および第三者ソースで公開されている主要ベンチマークをまとめます。
ベンチマーク | MiniMax M2.7 スコア | 補足 |
|---|---|---|
SWE-Pro(ソフトウェアエンジニアリング) | 56.22% | GPT-5.3-Codex相当 |
SWE-bench Verified | 約78% | Claude Opus系と互角 |
SWE Multilingual | 76.5% | 多言語コード生成 |
Terminal Bench 2 | 57.0% | ターミナル操作 |
VIBE-Pro | 55.6% | - |
NL2Repo | 39.8% | 自然言語→リポジトリ生成 |
GDPval-AA(オフィス生産性) | ELO 1495 | オープンソース最高水準 |
Toolathon(ツール使用) | 46.3% | - |
MM Claw | 62.7% | - |
MLE Bench Lite(ML研究) | 66.6% 平均メダル率 | Gemini 3.1と同水準 |
スキル遵守率 | 97% | 40+の複雑スキルで測定 |
現時点でのポジション: オープンソース系ではSOTA級、プロプライエタリを含めてもClaude Opus / GPT-5.4と互角〜一部同等という位置づけです。ただし最大ベンチマーク上限が要求される用途ではClaude Opus系が上回る場面もあり、すべての領域で1位というわけではない 点は正確に把握しておく必要があります。
出典: MiniMax 公式ニュース
MiniMax M2.7の料金・プラン
公式プラットフォーム(platform.minimax.io)で公表されているAPI料金は次のとおりです。
項目 | M2.7の料金 |
|---|---|
入力トークン | $0.30 / 100万トークン |
出力トークン | $1.20 / 100万トークン |
キャッシュヒット時入力 | 約$0.06 / 100万トークン(公式ニュース比較表) |
提供モデル |
|
価格推移 | M2.5から据え置き |
契約プラン
- Token Plan(platform.minimax.io/subscribe/token-plan): API利用者向けの基本プラン
- Coding Plan(platform.minimax.io/subscribe/coding-plan): コード生成用途向け
- MiniMax Agent(agent.minimax.io): ノーコードでM2.7を利用できるWebアプリ
- 紹介プログラム: 紹介者に10%キャッシュバック、被紹介者に10%割引
第三者プロバイダ経由の利用
OpenRouter など第三者APIプロバイダでも同価格帯で提供されており、既存のOpenRouter統合があればそのまま切り替えが可能です(openrouter.ai/minimax/minimax-m2.7)。
Claude / GPT / Geminiとの料金比較
モデル | 入力単価 | 出力単価 | ライセンス |
|---|---|---|---|
MiniMax M2.7 | $0.30 / 1M | $1.20 / 1M | Modified MIT(オープンウェイト) |
Claude Opus 4.6 | 約$15 / 1M | 約$75 / 1M | プロプライエタリ |
GPT-5.4 Mini | $0.75 / 1M | $3.00 / 1M | プロプライエタリ |
Gemini 3.1 Pro | 約$1.25 / 1M | 約$10 / 1M | プロプライエタリ |
参考: 生成AIツールの料金比較 / Claude料金 / ChatGPT料金
MiniMax M2.7の使い方
MiniMax M2.7には、大きく分けて4つの利用経路があります。用途とスキルに応じて選び分けましょう。
1. ノーコードで試す(MiniMax Agent)
もっとも手軽なのは、Web UIの agent.minimax.io にアクセスし、アカウントを作成して試す方法です。プロンプトを入れるだけでM2.7の能力を試せます。非エンジニアや、まず挙動を確認したい読者向けです。
2. 公式APIを使う
- platform.minimax.io でアカウント作成・APIキー発行
- Token Plan または Coding Plan を契約
- OpenAI互換のエンドポイントに対してREST APIでリクエストを送る
- モデル名は
MiniMax-M2.7または高速版MiniMax-M2.7-highspeed
エージェント用途で推奨される推論パラメータは temperature=1.0, top_p=0.95, top_k=40 です(Hugging Faceモデルカード準拠)。
3. 第三者プロバイダ(OpenRouter)経由
既にOpenRouterを使っている場合は、モデル名を minimax/minimax-m2.7 に切り替えるだけで利用できます。課金はOpenRouter側に集約できるため、複数モデルを試しているチームには便利 です。
4. セルフホスト(オンプレ / プライベートクラウド)
Modified MITのオープンウェイトを使って、自社環境にホストする構成です。以下のフレームワークに対応しています。
- vLLM(推奨)
- SGLang(推奨)
- Transformers
- ModelScope
- NVIDIA NIM(build.nvidia.com/minimaxai/minimax-m2.7 で無料GPUエンドポイント)
NVIDIAによると、Blackwell Ultra上でvLLMで2.5倍、SGLangで2.7倍 のスループット向上が報告されています。
ハードウェア要件: 総229Bパラメータのため、フル精度ではマルチGPU環境が前提です。Unslothが提供するGGUF量子化版(unsloth/MiniMax-M2.7-GGUF)やFP8量子化で軽量化できますが、一般的なゲーミングPC単体での快適な運用は現実的ではありません。
MiniMax M2.7と他モデルの違い
主要なフラッグシップモデルと比べた位置づけをまとめます。
比較ポイント | MiniMax M2.7 | Claude Opus 4.6 | GPT-5.4 | Gemini 3.1 Pro |
|---|---|---|---|---|
開発元 | MiniMax(中国) | Anthropic(米国) | OpenAI(米国) | Google DeepMind(米国) |
SWE-Pro | 56.22% | 約55%前後 | 約57〜58% | 非公開 |
コンテキスト長 | 約200K | 200K | 256K〜 | 1M(Pro) |
入力単価 | $0.30 / 1M | 約$15 / 1M | 約$2.50 / 1M | 約$1.25 / 1M |
出力単価 | $1.20 / 1M | 約$75 / 1M | 約$10 / 1M | 約$10 / 1M |
ライセンス | Modified MIT | プロプライエタリ | プロプライエタリ | プロプライエタリ |
セルフホスト | 可 | 不可 | 不可 | 不可 |
強みの領域 | コスト・エージェント・OSS | 文章生成・長文分析 | 総合力・推論 | マルチモーダル・長文 |
データ所在地 | 中国(公式ホスト時) | 米国 | 米国 | 米国 |
M2.7が光る場面
- エージェントで大量のツール呼び出し・シェル実行をする構成
- 自社インフラで完結させたい、オフラインで動かしたい要件
- 予算の上限が厳しく、Claude Opus 4.6を使いたいが料金で断念しているケース
M2.7より他モデルが向く場面
- 日本語の長文執筆・要約品質で最高水準を求める場合 → Claude Opus 4.6
- 総合的な推論・汎用的な対話・エコシステムの広さ → GPT-5.4
- マルチモーダル(画像・動画・音声)で1Mコンテキストを活かしたい → Gemini 3.1 Pro
参考: Claudeとは / ChatGPTとは / Geminiとは / Gemini 3.1 Proとは
MiniMax M2.7の制約と注意点
料金・性能のインパクトが大きい一方で、実務で採用する際に押さえるべき制約もあります。
1. データガバナンス(中国ベンダー)
MiniMaxは中国・上海のスタートアップです。公式ホスト版API(platform.minimax.io)を使う場合、リクエスト・レスポンスが中国側サーバーで処理される可能性があります。
- 個人情報・社内機密・顧客データを含むリクエストを送る場合は、法務・セキュリティ部門の確認が必須
- 金融・医療・官公庁など規制業種では、オープンウェイトをオンプレまたはプライベートクラウドでセルフホストする運用を推奨
- 試験利用の段階でも、本物の機密データではなくサンプルデータで検証するのが安全
2. ハードウェア要件
- 総パラメータ229Bは、フル精度推論にはマルチGPU(H100/H200/Blackwell Ultraクラス)が必要
- FP8量子化、Unslothが配布するGGUFで軽量化できるが、一般的なゲーミングPC単体運用は非現実的
- セルフホストを検討するなら、推論GPUの確保・クラスタ管理の運用コストを事前に見積もること
3. ライセンス(Modified MIT)の条項確認
ライセンスは基本的にMITベースですが、「Modified」部分の具体条項は必ず利用前に公式リポジトリで確認してください。商用利用可否・再配布条件などは各社法務でチェックすることを推奨します。
- GitHub: github.com/MiniMax-AI/MiniMax-M2.7
- Hugging Face: huggingface.co/MiniMaxAI/MiniMax-M2.7
4. エンタープライズサポート
OpenAI / Anthropic / Google と比較すると、MiniMaxは日本国内でのエンタープライズ導入実績がまだ限られています。 SLA・窓口対応・インシデント対応の体制は、大手ベンダーに劣る可能性があります。PoC段階で確認しておきたいポイントです。
5. 「自己進化」の正確な理解
繰り返しになりますが、ユーザーが触るM2.7は勝手に進化し続けるモデルではありません。 「自己進化」はMiniMaxが内部開発で活用した手法を公開したものであり、エンドユーザーは通常のLLMとして利用します。マーケティング上のバズワードと技術的実態の切り分けが重要です。
参考: 生成AI セキュリティ リスク
MiniMax M2.7はこんな人におすすめ
以下のニーズに当てはまる方にとって、MiniMax M2.7は有力な選択肢になります。
- 大量のAPI呼び出しをするエージェント/自動化基盤を構築したいエンジニア — 料金インパクトが最も効く用途
- Claude Opus 4.6クラスの性能をオープンソースで使いたいチーム — セルフホスト前提のアーキテクチャを組める
- コード生成・ターミナル操作を含む開発支援ワークフローを自動化したい開発者 — SWE-Pro 56.22% / Terminal Bench 57.0%の性能
- 自社環境にLLMを置きたい金融・医療・官公庁の技術選定担当者 — オンプレ運用で規制要件を満たせる
- OpenRouter経由で複数モデルをA/Bテストしているチーム — モデル名を切り替えるだけで試せる
MiniMax M2.7をおすすめしない人
一方、以下に当てはまる場合は別のモデルを検討する方が合理的です。
- 日本語の長文執筆・要約品質でトップクラスを求める個人利用者 — 用途によってはClaude Opus 4.6のほうが安定
- 機微情報を公式ホスト版APIに送信せざるを得ない組織 — セルフホストの体制が組めない場合は中国リージョンへの送信リスクが残る
- GPU調達・マルチGPU運用のリソースがないチーム — セルフホストの恩恵が受けにくい
- 音声・動画を含むマルチモーダル処理をメインにしたい場合 — Gemini 3.1 Proのほうが適する
- エンタープライズSLA・日本語での公式サポートが必須の企業 — 現時点ではOpenAI / Anthropic / Google系のほうが実績が豊富
MiniMax M2.7と関連ツールの組み合わせ
MiniMax M2.7は「すべてをM2.7で」と考えるより、既存のAIツール群と組み合わせて使うのが現実的です。用途別の選び分けを整理しました。
用途 | 推奨構成 |
|---|---|
社内エージェント基盤の推論バックエンド | M2.7(セルフホスト) + OpenClaw / Claude Code をクライアントに |
コード生成の補助(エディタ統合) | Cursor / Claude Code / OpenClawのバックエンドとしてM2.7を検討 |
長文ドキュメント生成・顧客向けライティング | Claude Opus 4.6(品質)+ M2.7(下書き量産) |
マルチモーダル処理 | Gemini 3.1 Pro をメインに、テキスト特化部分をM2.7でコスト最適化 |
研究・ML開発のアシスタント | M2.7(MLE Bench Lite 66.6%) |
MiniMax M2.7に関するFAQ
Q1. MiniMax M2.7とMiniMax M2.5の違いは?
最大の違いは、自己進化メカニズム(モデル自身がagent harnessコードを改善する仕組み)を内部開発に取り入れたかどうか です。M2.7はこの仕組みで内部評価約30%の性能向上を実現しています。API料金はM2.5から据え置きのため、特に理由がなければM2.7を選ぶのが合理的 です。
Q2. MiniMax M2.7は無料で使えますか?
公式APIは有料(入力$0.30 / 出力$1.20 per 1M)ですが、NVIDIA NIM の無料GPUエンドポイント(build.nvidia.com)や、Hugging Faceのオープンウェイト(自環境での推論)を利用すれば、試用段階は実質無料〜低コストで試せます。 MiniMax Agent(ノーコード版)にも利用枠がある場合があります。
Q3. 日本語には対応していますか?
多言語対応モデルのため、日本語プロンプトでも基本動作します。ただし、日本語の長文生成品質ではClaude Opus 4.6やGPT-5.4のほうが現時点で安定する傾向があります。コード生成・エージェント用途は日本語指示でも問題なく機能するケースが多いです。
Q4. MiniMax M2.7を業務で使う場合、データはどこに保管されますか?
公式ホスト版API(platform.minimax.io)を使う場合、処理は中国側サーバーで行われる可能性 があります。機微データを扱う場合は、オープンウェイトをオンプレミスやプライベートクラウドでセルフホストする運用が推奨です。契約前にデータ処理地域・保管ポリシーをMiniMax側に必ず確認してください。
Q5. セルフホストに必要なスペックは?
総229Bパラメータのため、フル精度ではH100 / H200 / Blackwell Ultraクラスのマルチ構成が前提です。FP8量子化やUnslothのGGUF版で軽量化できますが、一般的なゲーミングPC単体では現実的ではありません。 vLLMまたはSGLangでの運用が公式推奨です。
Q6. Claude CodeやOpenClawからM2.7を使えますか?
OpenRouter経由で対応しているクライアントからは利用可能です。M2.7本体は推論エンジン側にある形で、Claude CodeやOpenClawのようなエージェントクライアントの「推論バックエンド」として選択できます。具体的な切り替え手順は各クライアントのドキュメントを参照してください。
Q7. 「自己進化」で、ユーザー側のM2.7も使うほど賢くなるのですか?
いいえ。 ユーザーが利用するM2.7は通常のLLMであり、自動で学習し続けるわけではありません。「自己進化」はMiniMaxが内部開発プロセスでM2.7を育てるために使った手法を公開したものです。次世代モデル(M2.9やM3)では、この仕組みを活かしたさらなる性能向上が期待される段階です。
まとめ
MiniMax M2.7は、Claude Opus 4.6やGPT-5.4に匹敵する性能を、入出力ともに圧倒的な低価格かつオープンウェイトで提供する 最新のAIモデルです。エージェント・コード生成・オフィス生産性を強みとし、SWE-Pro 56.22%・Terminal Bench 2 で 57.0%・GDPval-AA ELO 1495 という、オープンソース最高水準のベンチマーク結果を記録しています。
一方で、中国ベンダー提供のため公式ホスト版APIにはデータガバナンス上の検討が必要、セルフホストにはマルチGPUが必要、「自己進化」は内部開発手法の公開であってユーザーのM2.7が勝手に賢くなるわけではない など、正確に把握しておくべき前提もあります。
用途と規制要件に応じて、「M2.7をセルフホストでエージェント基盤にする」「Claude Opus 4.6やGemini 3.1 Proと組み合わせて使い分ける」 といったハイブリッド運用が、日本企業にとっては現実的な選択肢になるでしょう。
次に読むべき記事
- 生成AIツールおすすめ比較 — 主要モデルの全体像を比較
- AIエージェント おすすめ 比較 — M2.7をどのエージェント基盤で使うか
- 生成AI セキュリティ リスク — 中国系モデル含むガバナンス観点
- Claudeとは / ChatGPTとは — 比較対象となる主要モデル
- MCPとは(Model Context Protocol) — M2.7のツール連携基盤
この記事の著者

AI革命
編集部
AI革命株式会社の編集部です。最新のAI技術動向から実践的な導入事例まで、企業のデジタル変革に役立つ情報をお届けしています。豊富な経験と専門知識を活かし、読者の皆様にとって価値のあるコンテンツを制作しています。
最新記事

楽天Rakuten AI 3.0=DeepSeek V3リブランド炎上のその後|GENIAC補助金・国産LLM定義問題の現在地【2026年7月続報】
2026/07/16

畜産業のAI活用事例|牛の個体識別・発情検知・給餌最適化・豚熱/鳥インフル対策まで【スマート畜産導入ガイド】
2026/07/16

IR・投資家広報のAI活用事例|exaBase IRアシスタント・決算短信要約・アナリスト対応自動化を徹底解説
2026/04/24

Thinking Machines Inklingとは?Mira Murati初のオープンウェイトモデルの性能・料金・使い方を完全解説【2026年7月速報】
2026/07/16

Gemini 3.5 Proとは?性能・料金・Flash比較・Claude Opus 4.8との違い【2026年7月最新・リリース目前】
2026/06/02

警備業界のAI活用事例|監視カメラ・異常行動検知・巡回省人化で人手不足を補う導入ガイド
2026/07/16
