LLM-jp-4とは?国立情報学研究所・約12兆トークン学習の国産LLMを徹底解説【2026年最新】

この記事のポイント
国立情報学研究所(NII)が開発した国産オープンソースLLM「LLM-jp-4」を徹底解説。Apache 2.0ライセンス・12兆トークン学習・日本語MT-Bench GPT-4o超えのスペック、8Bと32B-A3B MoEの使い分け、導入コスト、セットアップの注意点まで整理しています。
LLM-jp-4は、国立情報学研究所(NII)の大規模言語モデル研究開発センター(LLMC)が産官学2,600名以上のコミュニティと共同で開発し、2026年4月3日に公開した国産オープンソースLLMです。 約12兆トークンの事前学習・日本語MT-BenchでGPT-4oを上回るスコア・Apache License 2.0による商用利用可という3点が最大の特徴です。
この記事では、モデルスペック・ベンチマークの正確な読み方・料金と運用コスト・使い方・他の国産LLMとの違い・導入判断の材料まで、2026年6月時点の公式情報を基に整理します。
この記事でわかること
- LLM-jp-4の基本スペックとモデルラインナップ(8B/32B-A3B MoE/VLベータ)
- 約12兆トークン学習と日本語MT-BenchでのGPT-4o比較の正確な意味
- Apache 2.0商用利用時の実務的注意点
- 8Bモデルと32B-A3Bの使い分け(精度・コスト・用途の違い)
- セットアップ時の既知の問題(GGUF・vLLM設定等)
- 他の国産LLM(PLaMo 2.2・tsuzumi 2・Sarashina 2・Swallow)との比較
- こんな組織におすすめ/おすすめしない判断基準
想定読者
- 日本語に強いオープンソースLLMを自社基盤や研究用途で検討しているエンジニア・AI担当
- データ主権・オンプレ推論を重視する企業でLLM導入を進めるPM
- LLM-jpシリーズや他の国産LLMとの違いを整理したいリサーチャー
LLM-jp-4の基本情報
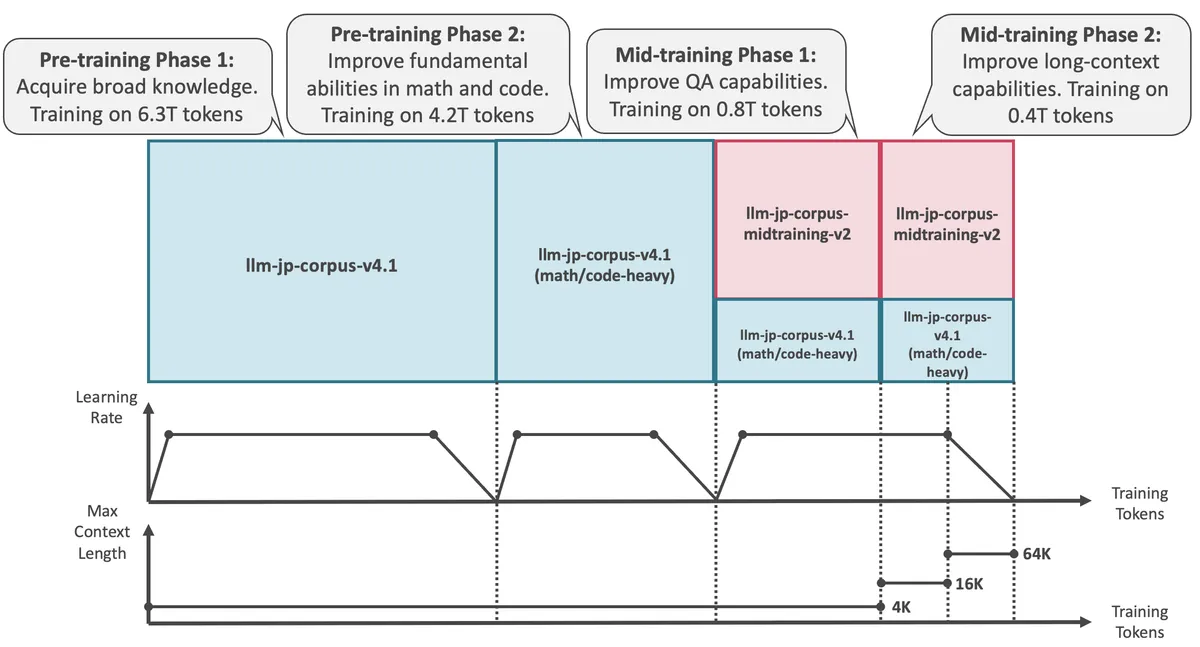
出典: LLM-jp-4-8b-instruct モデルカード(Hugging Face)
LLM-jp-4は、「日本で作り、日本のデータで強化し、誰でも商用利用できる」 という方針を一貫して掲げた国産オープンソースLLMの第4世代です。LLM-jp-3(最大172B Dense型)を経て、2026年4月にMoE採用・12兆トークン学習という設計転換を果たし、8Bと32B-A3Bの2系統で公開されました。
開発元と公開日
項目 | 内容 |
|---|---|
正式名称 | LLM-jp-4 |
開発元 | 国立情報学研究所(NII)/大規模言語モデル研究開発センター(LLMC) |
協力体制 | LLM-jpコミュニティ(2,600名以上の研究者・技術者) |
参画機関 | 早稲田大学・東北大学・東京大学・東京科学大学・名古屋大学等 |
公開日 | 2026年4月3日 |
提供形態 | Hugging Faceでモデル重みを配布(公式APIなし) |
ライセンス | Apache License 2.0(商用利用可) |
学習計算資源 | ABCI 3.0(産業技術総合研究所/NVIDIA H200 × 6,128基) |
公式サイト | https://llm-jp.nii.ac.jp/ |
モデル配布 | https://huggingface.co/llm-jp |
資金 | 文部科学省補助金「生成AIモデルの透明性・信頼性確保のための研究開発拠点形成」 |
LLM-jpシリーズの変遷
LLM-jpは2022年から継続的にモデルを公開してきた日本発のオープンLLMプロジェクトです。LLM-jp-4はその第4世代にあたります。
世代 | 主な公開時期 | 代表モデル | 特徴 |
|---|---|---|---|
LLM-jp-1系 | 2023年 | 13B | 初期世代。日英混合の事前学習 |
LLM-jp-3系 | 2024年9月〜12月 | 172B(2024年12月正式版) | GPT-3.5超えを標榜した大型Denseモデル |
LLM-jp-3.1系 | 2025年 | 8×13B MoEほか | 指示追従性能を改善(8×13B-instruct4でGPT-4超え報告) |
LLM-jp-4系 | 2026年4月3日 | 8B / 32B-A3B MoE / VLベータ | MoE採用・12兆トークン学習・Apache 2.0 |
LLM-jp-3は「とにかく大きく」する方向で172Bを公開しましたが、LLM-jp-4は大型化より効率化(MoE採用)と日本語データの質を重視した設計に方針を転換しました。自前ホスティングのハードルを下げながら日本語能力を底上げする、実運用寄りの設計変更です。
提供形態とライセンス(Apache 2.0の実務的な意味)
LLM-jp-4はHugging Faceでモデル重みが公開されており、自前の推論環境で動かす前提のプロジェクトです。公式APIサービスは提供されていません。
- ライセンス: Apache License 2.0
- 商用利用: 可(制限なし)
- 再配布: 可(Apache 2.0ライセンスのコピーを含めること)
- 改変: 可(変更した旨の明示義務あり)
- 追加契約: 不要
Apache 2.0を商用利用する際の実務上の注意点:
Apache 2.0は非常に緩いライセンスですが、完全なフリーではなく以下の義務があります。
- ライセンス表示義務:モデル/ツールを配布する場合、Apache 2.0ライセンスのコピーを含める
- 変更明示義務:モデルを改変・ファインチューニングして配布する場合、変更した旨を明示する
- 学習データのライセンス確認:モデル重みはApache 2.0ですが、学習コーパスの一部はライセンス上の理由で非公開。コーパスを独自利用する場合は個別確認が必要
エンドユーザーへの商用サービスとして組み込む場合(チャットbot・業務システム等)は、これらの義務を確認した上で導入してください。
また、LLM-jp公式のライセンス指針では、以下の用途を禁止しています:
- 知的財産権の侵害
- 人権侵害・誹謗中傷
- 弁護士・医師・会計士・税理士等の資格業務の代行
- 法的認可が必要な活動への利用
LLM-jp-4のモデルラインナップ(2026年6月時点)
LLM-jp-4は用途ごとに複数のバリエーションが公開されています。8B Denseと32B-A3B MoEの2系統が軸で、それぞれにbase・instruct・thinkingの派生モデルが用意されている構造です。
公開済みモデル一覧(2026年4月3日時点)
モデル名 | 総パラメータ | アクティブ | アーキテクチャ | 主な用途 |
|---|---|---|---|---|
llm-jp-4-8b-base | 約8.59B | 8.59B(Dense) | Llama系 | 事前学習のみ。研究・追加学習用 |
llm-jp-4-8b-instruct | 約8.59B | 8.59B(Dense) | Llama系 | SFT+DPOで指示応答に調整済み |
llm-jp-4-8b-thinking | 約8.59B | 8.59B(Dense) | Llama系 | 思考モード対応。Chain-of-Thought |
llm-jp-4-32b-a3b-base | 約321億 | 約38億 | Qwen3-MoE系 | MoE事前学習モデル |
llm-jp-4-32b-a3b-instruct | 約321億 | 約38億 | Qwen3-MoE系 | MoE指示応答モデル |
llm-jp-4-32b-a3b-thinking | 約321億 | 約38億 | Qwen3-MoE系 | MoE+思考モード |
llm-jp-4-vl-9b-beta | 約9B(LLM 8.6B+Vision 0.4B) | — | SigLIP2+LLM-jp-4-8b-instruct | マルチモーダル(画像+文)ベータ版 |
全モデル共通のスペック:
- コンテキスト長: 65,536トークン(約6万5千トークン)
- データ型: BF16
- トークナイザー: llm-jp-tokenizer v4.0(Unigram byte-fallback方式)
- チャットテンプレート: OpenAI Harmonyフォーマット互換(ただし付属トークナイザーの使用が必須)
8Bモデルと32B-A3Bモデルの使い分け比較
どちらを選ぶかは「精度要件」「利用可能なGPU」「実行速度」の3点で決まります。
比較軸 | 8B Dense | 32B-A3B MoE |
|---|---|---|
総パラメータ | 約8.59B | 約321億 |
推論時アクティブ | 8.59B | 約38億(MoEの恩恵) |
推論コスト感 | 8B相当 | 実質4B相当(高速) |
必要VRAM(BF16) | 約17GB以上 | 32B相当(H100×1 or A100 80GB×2以上) |
日本語MT-Benchスコア | 7.54 | 7.82 |
英語MT-Benchスコア | 7.79 | 7.86 |
JSON構造化出力精度(実務検証) | 約61%(フォーマット遵守が不安定) | 約93%(実用圏内) |
1枚GPUで動作 | 可(RTX 4090でも動作報告あり) | 困難(大VRAM GPUが必要) |
向いている用途 | PoC・プロトタイプ・チャットbot | 本番業務・高精度な構造化出力・RAG |
まず8B-instructで試し、精度・出力フォーマットの安定性が必要なタスクは32B-A3Bへ移行する というステップが実務的です。構造化出力(JSONメタデータ抽出等)を業務利用する場合は、8Bの61%精度では実用に耐えないケースが多く、最初から32B-A3Bを選ぶべきタスクもあります。
thinkingモデルの特徴
thinking版はChain-of-Thought(思考プロセス)に対応したバリアントです。
reasoning_effortパラメータで3段階(low / medium / high)の思考深度を制御- 内部で推論ステップを展開し、最終回答の前に「考え」を挟める
- 日本語MT-Bench(8B thinking): low=7.23、medium=7.54
- 複雑な推論・計算・コードデバッグ・高度な要約に優位
まずmediumで試して、要件に応じてlow/highに振り分けるのが現実的です。highは応答が遅くなるため、応答速度が重要なリアルタイムアプリには向きません。
LLM-jp-4-VL(ビジョンモデル・ベータ)
LLM-jp-4-VL 9B betaは2026年4月14日に公開されたマルチモーダル派生モデルです。
項目 | 内容 |
|---|---|
公開日 | 2026年4月14日 |
パラメータ数 | 約9B(言語 8.6B+ビジョン 0.4B) |
ビジョンエンコーダー | SigLIP2 |
学習データ | 日英合計約180Bトークン(約3,340万事例) |
ベンチマーク平均 | 70.8(Qwen3-VL-8B: 71.1とほぼ同等) |
日本文化・常識タスク | Qwen3-VLより優位 |
学習効率 | Qwen3-VLの学習トークン数の約1/10で同等性能 |
現状 | ベータ版。本番投入は推奨されない |
OCRや図表解釈を日本語で完結させたい研究・評価用途では現時点でも試せますが、本番ワークロードへの組み込みは正式版リリース後が安全です。
2026年度中に予定されているリリース
モデル/成果物 | 内容 | 状態 |
|---|---|---|
LLM-jp-4 32B Dense | MoEなし大型Denseモデル | 未公開(2026年度中予定) |
LLM-jp-4 332B-A31B | 総3,320億・アクティブ310億のMoE(国産オープンLLM最大クラス) | 未公開(2026年度中予定) |
軽量版モデル | 小パラメータバリエーション | 未公開(2026年度中予定) |
LLM-jp-4-VL 正式版 | VLモデル正式版 | 未公開(2026年度中予定) |
Jagleデータセット | 画像キャプションデータセット | 未公開(2026年度中予定) |
特に332B-A31Bは、国産オープンLLMとして過去最大クラスの規模になる見通しです。公開時期は未確定のため、公式サイトのアナウンスで確認してください。
約12兆トークン学習とベンチマーク性能
出典: 国立情報学研究所 公式ニュースリリース(2026年4月3日)
LLM-jp-4の最大の特徴は、約12兆トークンの学習量と日本語MT-BenchでGPT-4oを上回るスコアです。ただし、これらは特定条件下での数値であり、正確な意味を把握しておく必要があります。
学習データ(LLM-jp Corpus v4)の内訳
NIIの公式発表では「約12兆トークンで事前学習した」と発表されています。
区分 | トークン数 |
|---|---|
事前学習 | 約10.5兆トークン |
中間学習 | 約1.2兆トークン |
合計(NIIの発表) | 約12兆トークン |
コーパス総量(採用前のプール含む): 約19.5兆トークン
言語別内訳(採用後):
言語 | トークン数 |
|---|---|
英語 | 約17.8兆トークン |
日本語 | 約7,000億トークン |
中国語・韓国語等 | 約8,500億トークン |
プログラムコード | 約2,000億トークン |
コーパス全体では英語が多数を占めますが、日本語を約7,000億トークン用意している点が、日本語特化LLMとしての差別化です。日本語データソースには以下が含まれます。
- インターネット公開データ(多段階フィルタリング適用)
- 国立国会図書館のデジタル資料
- 政府の公文書・国会議事録
- 国立国語研究所のNINJAL Webコーパス(whole-NWJC)
- 合成データ
コーパスの透明性: LLM-jp Corpus v4は2025年6月30日にGitLabで公開済み。LLM-jp PDF Collection v1は2026年5月に追加公開されました。
事後学習(instruct/thinking版):
- SFT(Supervised Fine-Tuning): 日英22データセットを使った指示追従学習
- DPO(Direct Preference Optimization): 人間の選好に合わせた調整
- 強化学習(RLHF)は不使用
ベンチマーク性能(公式発表)
日本語MT-Bench(日本語対話理解)
モデル | スコア |
|---|---|
LLM-jp-4 32B-A3B | 7.82 |
LLM-jp-4 8B | 7.54 |
GPT-4o | 7.29 |
Qwen3-8B | 7.14 |
英語MT-Bench(英語対話理解)
モデル | スコア |
|---|---|
LLM-jp-4 32B-A3B | 7.86 |
LLM-jp-4 8B | 7.79 |
GPT-4o | 7.69 |
Qwen3-8B | 7.69 |
llm-jp-eval 42タスク評価では、LLM-jp-4 32B-A3BはQwen3-8Bと同等の水準を実現しています。
「GPT-4o超え」の正確な意味
日本語MT-BenchでGPT-4oを上回ったという結果は事実です。しかし、MT-Benchは対話型タスクに特化した評価であり、以下の点を補足する必要があります。
- 「日本語の自然な対話・指示応答」での競合力: GPT-4oや他のオープンモデルに劣らない水準にある
- 推論・数学・コーディング・マルチモーダル等の総合力: GPT-4oが依然として優位な傾向
- ベンチマーク外のタスク: JSON構造化出力(8B: 61%)など、タスクによって精度に大きな差
「日本語の対話と指示応答でGPT-4oに十分競合できるオープン代替モデル」と位置付けて検証するのが、誤解を招かない評価姿勢です。
学習計算資源(ABCI 3.0)
LLM-jp-4は産業技術総合研究所が運用するスーパーコンピューターABCI 3.0で学習されました。
- NVIDIA H200 GPU × 6,128基(766台の計算ノード)
- ノードあたり2TB DDR5メモリ
- InfiniBand高速ネットワーク、75PBの共有ストレージ
国産の公開LLMとしては最大級の計算資源投入であり、国の計算基盤を使って日本語LLMを継続的に更新できるというプロジェクト構造がLLM-jpシリーズの持続性を支えています。
できること・主な活用シーン

LLM-jp-4は汎用的な生成AIとして幅広く使えますが、日本語テキストの理解・生成と、オンプレ/クローズド環境での運用に特に強みがあります。
用途別ユースケース
用途 | 特徴 | 実績・精度 | 推奨モデル |
|---|---|---|---|
日本語チャットbot・カスタマーサポート | 日本語MT-Bench高スコア、Apache 2.0で商用可 | MT-Bench 7.54〜7.82 | 8b-instruct |
社内文書のRAG・検索 | 65Kトークンコンテキスト、オンプレでデータ主権確保 | 長文処理に対応 | 8b-instruct / 32b-a3b |
JSONメタデータ抽出・構造化出力 | 高精度な構造化を要求するタスク | 32B-A3B: 93%、8B: 61% | 32b-a3b-instruct |
コード生成・ステップ推論 | thinking版+reasoning_effort制御 | MT-Bench 7.54(8B thinking) | 8b-thinking / 32b-a3b-thinking |
研究・LLMの追加学習ベース | Apache 2.0、学習データ一部公開 | 透明性が高い | 8b-base / 32b-a3b-base |
日本語OCR・画像+文の処理 | SigLIP2ベースのVL対応 | 全タスク平均70.8(ベータ) | vl-9b-beta(研究用) |
実務検証事例(Qiita報告より):
- 32B-A3Bで50項目のJSONメタデータ抽出を実施 → 93%精度(gpt-oss:120Bの81秒に対し約145秒/実行)
- 8Bでは同タスクで61%精度(サフィックス・区切り文字の遵守で問題発生)
- 65,000トークンのコンテキスト対応により、技術ドキュメント数十本の一括Q&Aが可能
料金・運用コスト
LLM-jp-4そのものは無料ですが、動かすためのインフラコストは自社負担になる点がAPI課金型との最大の違いです。
モデル自体の料金
項目 | 内容 |
|---|---|
モデルダウンロード | 無料(Hugging Face経由) |
公式API利用料 | なし(公式API非提供) |
ライセンス費用 | 不要(Apache 2.0) |
商用利用 | 可(追加契約不要) |
GPU要件の目安(コミュニティ検証ベース)
公式の推論VRAM要件は明示されていません。以下はコミュニティ検証・Hugging Faceの情報から得られた目安です。
モデル | 必要VRAM(BF16) | Int4量子化時 | 動作確認GPU例 |
|---|---|---|---|
8B | 約17GB以上 | 約8GB程度 | RTX 4090 / A100 40GB / L40S |
32B-A3B(MoE) | 32B相当(MoE全体) | — | H100×1 / A100 80GB×2以上 |
VL 9B beta | 約18GB以上 | — | A100 40GB以上 |
運用パターン別コストの考え方
運用パターン | コスト目安 | 向いているケース |
|---|---|---|
自社オンプレGPU(H100/H200) | 初期投資が高いが長期のトークン単価は最安 | 大量・長期運用、機密データを一切社外に出せない業種 |
クラウドGPU(AWS/GCP/Azure/さくら) | H100 1枚あたり時間課金(従量課金) | PoC・中規模運用・スケールが読めないフェーズ |
国内LLM推論サービス経由 | 事業者によるホスティング料金 | 自前運用を避けたいが国産モデルを使いたい場合 |
「APIコストは発生しないが、GPU時間は発生する」 という構造を最初に理解しておくことが、導入判断のポイントです。ChatGPT APIとのコスト比較は、月次のトークン使用量とGPUの稼働率で大きく変わります。大量・長期利用であれば自前GPUが有利になりますが、小規模利用ではAPIサービスのほうが安い場合が多いです。
生成AIのコスト比較については、生成AI料金比較も参考になります。
セットアップと使い方

LLM-jp-4はAPI提供がないため、Hugging Faceからモデルをダウンロードして自前の推論環境で動かすのが基本の使い方です。
環境の準備
必要なもの | 内容 |
|---|---|
GPUマシン | VRAM 17GB以上(8Bの場合)。クラウドGPUでも可 |
Python | 3.10以上 |
PyTorch | 2.x |
Transformers | 4.40以上 |
Hugging Faceアカウント | モデルカード同意のため |
公式サンプル |
Hugging Face Transformersで動かす最小例
公式cookbookをベースにすると、以下のステップでinstructモデルを呼び出せます。
pip install transformers torch accelerateで依存関係をインストールfrom transformers import AutoTokenizer, AutoModelForCausalLMをインポートllm-jp/llm-jp-4-8b-instructを指定してトークナイザーとモデルをロード(trust_remote_code=Trueが必要)- チャット形式のメッセージを構築し、
apply_chat_templateで整形 model.generateで推論、tokenizer.decodeで出力を取得
OpenAI Harmony互換のチャットテンプレートが用意されているため、ChatGPT系のAPI呼び出しコードからの移植がしやすいのが利点です。
本番向けの推論エンジン
エンジン | 特徴 | 向いているケース |
|---|---|---|
vLLM | OpenAI互換APIエンドポイントを構築可能。高スループット | 本番サービス、OpenAI互換で移行したい場合 |
TGI(Text Generation Inference) | Hugging Face製。量子化・テンソル並列対応 | 量子化運用・マルチGPU |
llama.cpp / Ollama | GGUF形式で軽量動作 | 個人利用・エッジ(GGUFの注意点あり) |
既知の問題と実装時の注意点(重要)
LLM-jp-4を実際にセットアップするにあたって、他の記事ではあまり触れられていない実装上の落とし穴があります。導入前に確認してください。
① trust_remote_code=Trueが必須
llm-jp-tokenizer v4.0はカスタムトークナイザーのため、ロード時にtrust_remote_code=Trueの指定が必要です。これを忘れると正しくロードできません。
② vLLMでthinkingモデルを使う場合はreasoningパーサーが必要
thinking(推論)モデルをvLLMで動かす際、デフォルト設定では思考トークン(内部推論ステップ)が出力テキストに混入する問題があります。vLLM設定でカスタムreasoningパーサーを指定しないと、エンドユーザーへの回答に推論ログが含まれる場合があります。
③ OllamaはGGUF形式が必要だが公式版が未提供
Ollamaで動かすにはGGUF形式が必要ですが、公式からはGGUFが提供されていません。コミュニティがQwen3 MoEアーキテクチャをGGUFに変換した版を公開していますが、以下の注意点があります。
- トークナイザーの非互換問題(Unigram vs BPE の自動判定ミス)が発生することがある
- 量子化時の精度低下リスクがある
- コミュニティ提供のため、公式サポートなし
LLM-jp-4を本番で使う場合は、公式のBF16モデル + vLLMまたはTGI の組み合わせが最も安定しています。
④ BF16精度を推奨
量子化(Int4/Int8)はVRAM要件を下げられますが、精度低下リスクがあります。特に構造化出力タスク(JSON抽出等)では量子化による精度低下が大きく出る可能性があるため、品質を重視するタスクにはBF16での運用を推奨します。
他の国産LLM・海外モデルとの比較
LLM-jp-4は「産官学連携でつくられたApache 2.0の国産オープンLLM」という唯一性を持ちますが、他の国産LLMや海外オープンモデルとは得意領域が異なります。
主要な国産LLMとの比較(2026年6月時点)
モデル | 開発元 | 規模 | ライセンス/提供形態 | 特徴 |
|---|---|---|---|---|
LLM-jp-4 | NII/LLMC(産官学) | 8B / 32B-A3B MoE | Apache 2.0・重み配布 | フルオープン。学習データの透明性が高い。日本語MT-Bench上位 |
PLaMo 2.2 | Preferred Networks | スクラッチ訓練 | PFN提供 | JFBenchでGPT-5.1と同等スコア。Jaster最高スコア |
Sarashina 2 | SoftBank | 最大8×70B MoE(約460B)、1T級開発中 | 商用可ライセンス | 日本語特化。SoftBankクラウドとの統合 |
tsuzumi 2 | NTT | 600M〜7B | 商用ライセンス | 軽量・エッジ志向。NTTビジネスソリューション連携 |
Swallow | 東京科学大学ほか | 各種 | 研究用途中心 | Llama/Qwen系への日本語継続事前学習(CPT型) |
ELYZA | ELYZA | LLaMAベース | 商用版あり | LLaMAベース・ファインチューニング型 |
出典: LLM-jp Hugging Face 公式コレクション
LLM-jp-4の強み
他モデルと比べたLLM-jp-4の強みは3点に集約されます。
① フルオープン
モデル重み・トークナイザー・一部の学習コーパス・事後学習レシピまで公開。LLM-jpの学習プロセスの透明性は国産LLMの中でも特に高い水準にあります。「学習データに何が入っているか確認したい」という監査ニーズにも応えやすい構造です。
② 産官学連携による継続性
NIIが主導し、ABCI 3.0で学習できる枠組みがあるため、今後も世代更新が期待できる体制が整っています。民間企業の戦略変更に左右されない、国の研究インフラに支えられたプロジェクトです。
③ Apache 2.0の完全オープンライセンス
「個社の商用ライセンスに縛られたくない」「将来の追加学習にも自由にモデルを使いたい」「ライセンス監査コストを下げたい」というスタートアップ・研究機関にとって、最も選びやすい国産LLMです。
LLM-jp-4の弱み
弱み | 詳細 |
|---|---|
公式APIなし | 使うにはGPU基盤の準備が必須。すぐ呼び出せるサービスではない |
安全性チューニング未完了 | 公式モデルカードで「出力が人間の意図・安全性に調整されていない」と明記 |
マルチモーダルはベータ | VL正式版は2026年度中の予定 |
サポート体制 | 産官学プロジェクトのため、商用ベンダーのようなSLA・24/7サポートはない |
GGUF公式未提供 | Ollama等での軽量実行はコミュニティ頼り |
日本語応答の長さ | 日本語の回答が英語と比べて短くなる傾向との報告あり |
海外オープンモデルとの比較
海外の主要オープンモデル(Llama 4 / Qwen3 / Gemma 4 / DeepSeek V4等)と比較すると、LLM-jp-4は日本語ベンチマークに特化して最適化された国産モデルという位置づけです。
- 英語・中国語・コーディング等の汎用性能最大化ではなく、日本語対話品質の底上げに計算資源を投じている
- 総パラメータ・学習トークン数では海外トップモデル(40T規模)に劣るが、日本語の単位トークンあたりの効率で勝負する設計
- ライセンスの緩さ(Apache 2.0)は海外トップモデルと同等〜有利
英語主体のグローバル展開ならLlama 4 / Qwen3、日本語主体で国内向けビジネスならLLM-jp-4という棲み分けが実務的です。
生成AIツール全体の比較は、生成AIツールおすすめ比較でも整理しています。
導入時の注意点・セキュリティ
安全性チューニングが未完了であること
公式モデルカードには以下の注意書きが明記されています。
The models released here are in the early stages of our research and development and have not been tuned to ensure outputs align with human intent and safety considerations.(現時点のモデルは研究開発の初期段階であり、出力が人間の意図や安全性に沿うようにチューニングされていない)
本番アプリケーションに組み込む際には、入力のモデレーション・出力フィルタリング・NGワードや誤情報ガードレールの実装を前提に設計してください。特に医療・金融・法務領域での利用には追加の安全策が必要です。
オンプレ運用のセキュリティ管理責任
LLM-jp-4のローカル実行では、セキュリティ管理はすべて利用者の責任となります。
- モデル自体の脆弱性管理・運用環境のセキュリティ対策は自社で実施
- プロンプトインジェクション攻撃への対策が必要(悪意ある入力でシステムプロンプトを上書きされるリスク)
- システムプロンプトに認証情報・機密情報を記述しない(プロンプトが漏洩した場合のリスク)
- コミュニティ提供のGGUF等、非公式モデルは公式サポートなし
データ取り扱いとプライバシーのメリット
逆に、ローカル実行のメリットとして、外部へデータを一切送信せずに推論できる点があります。
- 医療・金融・法務・行政など、外部送信が制限される業種でも利用しやすい
- オンプレ/VPC内で完結する推論構成を組みやすい
- GDPR・個人情報保護法観点でのデータ主権を確保しやすい
「自社データを守りながら日本語LLMを使いたい」というニーズには、LLM-jp-4の運用モデルが素直に合致します。生成AIのセキュリティ対策全般については、生成AI セキュリティ リスクも参照してください。
最新アップデート・リリース履歴
日付 | 内容 |
|---|---|
2025年6月30日 | LLM-jp Corpus v4 公開(GitLab) |
2026年4月3日 | LLM-jp-4 8B・32B-A3Bモデル公開(thinkingバリアント含む) |
2026年4月14日 | LLM-jp-4-VL 9B beta 公開(マルチモーダル版) |
2026年5月 | LLM-jp PDF Collection v1 公開 |
2026年4月〜 | 大規模音声・音響データセット公開 |
2026年度中(予定) | LLM-jp-4 32B Dense、332B-A31B MoE、軽量版、VL正式版を順次公開予定 |
こんな組織・用途におすすめ/おすすめしない
LLM-jp-4は、ニーズと運用体制がかみ合うかどうかで「刺さる・刺さらない」がはっきり分かれます。
おすすめの組織・用途
ケース | 理由 |
|---|---|
日本語業務のLLMを自社GPUで運用したい企業 | オンプレ/クラウドGPUでデータを外に出さずに使える |
医療・金融・行政など機密データを扱う組織 | ローカル実行で外部送信ゼロの推論が可能 |
研究・LLMの追加学習を行う大学・研究機関 | Apache 2.0で改変・再配布が自由。学習データも一部公開 |
ライセンスコストを下げたいスタートアップ | 追加契約不要。ライセンス監査コストが低い |
日本語RAG・チャットbot基盤を構築する開発チーム | 日本語MT-Bench高スコア、65Kトークンの長文処理対応 |
国産LLMの世代更新を継続的に追いたい企業 | NIIが主導する長期プロジェクトで持続性が高い |
おすすめしない用途・状況
ケース | 理由 |
|---|---|
APIコールだけで手軽に使いたい場合 | 公式APIなし。自前またはサードパーティのホスティングが必須 |
安全性チューニング済みの即戦力を求める場合 | そのままエンドユーザーに出すにはガードレール設計が別途必要 |
GPU環境を持たない・構築できない組織 | モデルのダウンロードから推論サーバー構築まで技術力が必要 |
英語特化タスク・海外マルチリンガルを重視する場合 | Llama 4 / Qwen3等の英語主体モデルのほうが汎用性が高い |
マルチモーダルを本番前提で使いたい場合 | VLはベータ版。正式版待ちが現実的 |
企業向けSLA・24/7サポートを必要とする場合 | 産官学プロジェクトのため、商用ベンダーのSLA契約とは異なる |
AIエージェントやLLMの仕組みをより深く理解したい方は、AIエージェントとはも参考になります。
関連記事
国産LLMや生成AIツールの選定を進める際は、以下の記事も参考にしてください。
- 生成AIツールおすすめ比較 — 生成AIツール全体の比較
- 生成AI料金比較 — API・モデル別のコスト比較
- AIエージェントとは — LLMを使ったエージェント設計の基礎
- tsuzumi 2とは|NTT独自の軽量日本語LLMを徹底解説 — 国産軽量モデルとの比較
- 生成AI セキュリティ リスク — オンプレLLM運用のセキュリティ対策
- Qwen 3.5-Omniとは — 中国製オープンモデルとの比較
- Meta Llama 4 Scoutとは — 海外オープンモデルとの比較
よくある質問(FAQ)
Q1. LLM-jp-4は無料で使えますか?
はい。モデル重みはHugging Faceで無料公開されており、Apache License 2.0で商用利用も可能です。ただし公式APIは提供されていないため、実際に動かすGPU(自社オンプレまたはクラウド)のコストは別途必要です。
Q2. GPT-4oより高性能という理解で合っていますか?
日本語MT-Benchという対話特化ベンチマークでは、LLM-jp-4 8B(7.54)と32B-A3B(7.82)がGPT-4o(7.29)を上回ったと公式が発表しています。ただし、コーディング・推論・マルチモーダル等の広範なベンチマーク全体でGPT-4oを超えるという意味ではありません。日本語の対話と指示応答でGPT-4oに十分競合できるオープン代替として評価するのが正確です。
Q3. 8Bと32B-A3Bのどちらから始めるべきですか?
一般的な用途ならllm-jp-4-8b-instructから始めるのがおすすめです。1枚のGPUで動かせ、チャットや要約などの基本的な指示応答に調整済みです。ただし、JSON抽出などの構造化出力が必要なタスクでは8Bの精度(約61%)が実用に足らないケースがあるため、最初からllm-jp-4-32b-a3b-instructを検討してください。
Q4. Ollamaで動かせますか?
現時点では公式GGUFが提供されていないため、Ollamaでの動作にはコミュニティが変換したGGUF版が必要です。トークナイザーの非互換問題(Unigram vs BPEの自動判定ミス)が発生するケースがあり、精度低下リスクもあります。安定した本番利用にはvLLM + 公式BF16モデルの組み合わせを推奨します。
Q5. 法律・医療・金融のプロダクトにそのまま使えますか?
そのままエンドユーザーに提供する用途には推奨されません。 公式モデルカードで安全性チューニングが未完了と明記されており、ハルシネーションや不適切な出力のリスクがあります。規制業種での利用には、入力モデレーション・出力フィルタリング・ガードレール・人手レビューなどの追加設計を前提にしてください。
Q6. LLM-jp-3やLLM-jp-3.1から乗り換えるメリットはありますか?
あります。MoE採用で推論コストが低下しており、日本語コーパスも刷新されたため、同じGPU資源でより良い日本語応答が期待できます。ただし、LLM-jp-3.1をすでにファインチューニングして使っている場合は、既存プロンプトの挙動差の検証と追加学習モデルの再作成が必要になります。段階的な移行テストを行うのが安全です。
Q7. LLM-jp-4-VL(画像対応版)は本番に使えますか?
2026年6月時点ではベータ版のため、本番投入は推奨されません。 評価・研究用途であれば試せますが、正式版とJagleデータセットの公開待ちが現実的です。業務でマルチモーダルを使う必要がある場合は、他のマルチモーダルLLMと併用する構成も検討してください。
Q8. 332B-A31Bモデルはいつリリースされますか?
2026年6月時点では「2026年度中」とのみ発表されており、正確な公開日は未確定です。LLM-jp公式サイトのアナウンスを随時確認してください。総3,320億パラメータ・アクティブ310億のMoEという規模は、国産オープンLLMとして過去最大クラスになる見通しです。
Q9. Apache 2.0ライセンスで商用利用する際に注意すべき点はありますか?
主に2点です。①ライセンス表示義務(配布時にApache 2.0ライセンスのコピーを含める)、②変更明示義務(モデルを改変・ファインチューニングして配布する場合、変更した旨を明示する)。自社内でのみ利用・サービス提供する場合は追加の制約は少ないですが、外部に配布・OEM提供する場合はこれらの義務を確認してください。
この記事の著者

AI革命
編集部
AI革命株式会社の編集部です。最新のAI技術動向から実践的な導入事例まで、企業のデジタル変革に役立つ情報をお届けしています。豊富な経験と専門知識を活かし、読者の皆様にとって価値のあるコンテンツを制作しています。
最新記事

防衛産業のAI活用事例|自律防衛・ドローン監視・サイバー防衛・意思決定支援と日本の防衛省の取り組み【2026年最新】
2026/07/21

薬局チェーン本部の店舗運営管理とは|3原則・役割分担・KPI・2026年改定まで整理
2026/07/20

Qwen3.8-Max-Previewとは?2.4Tパラメータ・料金・使い方とFable 5/Qwen3.7 Maxとの違いを整理【2026年7月最新】
2026/07/20

Gemini 3.5 Proとは?リリース延期の最新状況・性能・料金・Flash/Claude Opus 4.8比較【2026年7月最新】
2026/06/02

AI研修に使える補助金・助成金まとめ【2026年最新】法人が従業員研修で使える制度と申請手順
2026/07/20

店舗数が増えるほど重要になる薬局チェーン本部の運営管理とは|規模拡大の落とし穴と本部機能の作り方
2026/07/20
