Meta Llama 4 Scout とは|17B MoE・10Mトークン context徹底解説
この記事のポイント
Metaが2025年に公開したオープンウェイトMoE型LLM「Llama 4 Scout」の仕組み・料金・10Mコンテキストの実力・Maverickや他モデルとの違いを2026年4月時点の最新情報で整理しました。
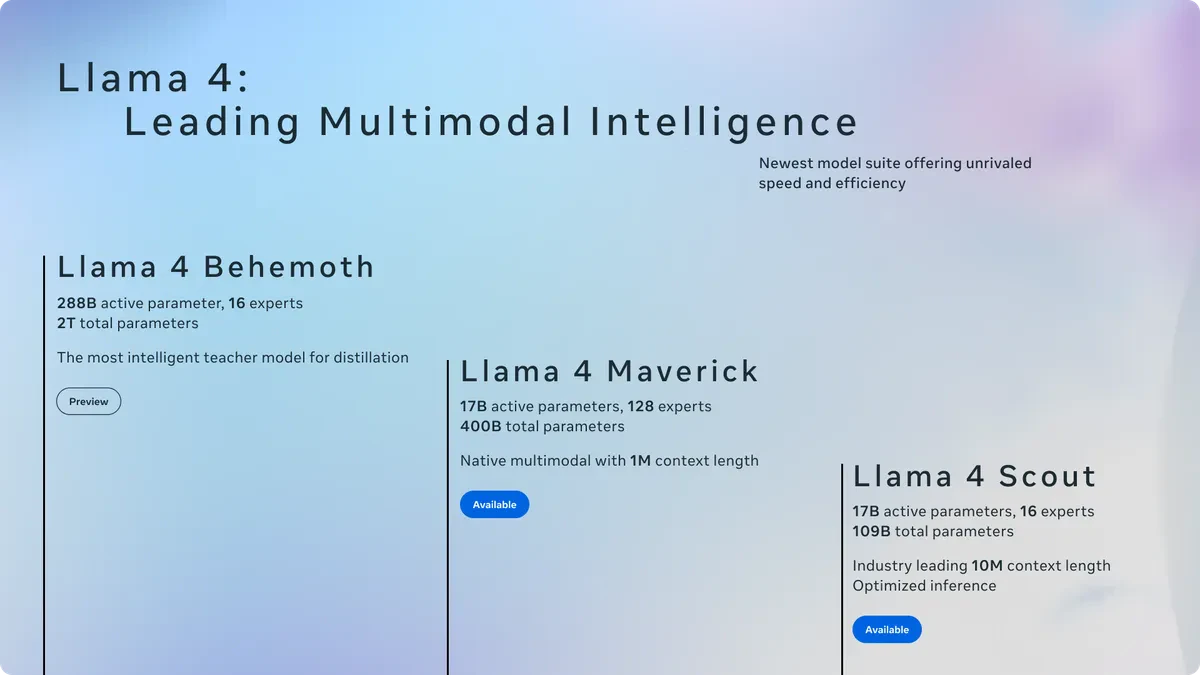
Meta Llama 4 Scout は、Meta が 2025 年 4 月に公開した、Llama 4 シリーズで最も軽量なオープンウェイトのマルチモーダル LLM です。 17B のアクティブパラメータと 16 エキスパートの Mixture-of-Experts(MoE)構成、そして公称 1,000 万(10M)トークンという桁外れのコンテキストウィンドウを、単一の NVIDIA H100(80GB)で動かせるように設計されている点が最大の特徴です。
この記事では、Scout の公式スペックと「10M コンテキスト」の実力、料金、他モデルとの違い、導入判断までを 2026 年 4 月時点の最新情報で整理します。
この記事でわかること
- Llama 4 Scout の基本スペックと、Llama 4 シリーズでの位置付け
- 17B MoE(109B 総パラメータ・16 エキスパート)の仕組みと、単一 H100 で動く理由
- 10M トークンコンテキストの公式主張と、第三者ベンチマークでの実測評価
- セルフホスト/主要マネージド API の料金目安と、無料で試す方法
- Maverick・Llama 3.1 405B・他オープンモデルとの比較
- 向いている用途・向いていない用途、ライセンス上の注意点
想定読者
- オープンウェイト LLM を自社のオンプレ/プライベートクラウドで検証したいエンジニア・インフラ担当
- 長文コンテキストやマルチモーダル活用を検討している AI 導入プロジェクトの PM
- Llama 4 Scout と Maverick、他のオープンモデルの違いを整理したいリサーチャー
Llama 4 Scout の基本スペック
Llama 4 Scout は、「オープンウェイトで単一 H100 GPU に収まり、マルチモーダル入力と 10M トークンの長文コンテキストを標榜する軽量モデル」 という立ち位置です。Llama 4 シリーズで初めて MoE を採用した世代の、エントリーモデルに位置付けられています。
Llama 4 Scout とはどのようなモデルか
公式(llama.com)の説明では、Scout は "Class-leading natively multimodal model that offers superior text and visual intelligence, single H100 GPU efficiency, and a 10M context window" と紹介されています。要点は次の 3 つです。
- ネイティブ・マルチモーダル:テキストと画像を同じモデルで扱える
- 単一 H100(80GB)で動作:BF16 でも 1 枚の H100 に収まる設計
- 10M トークンの長文コンテキスト(公式訴求値。実運用上の品質は後述)

出典: Hugging Face 公式モデルカード(meta-llama/Llama-4-Scout-17B-16E-Instruct)
公式スペック一覧
2026 年 4 月時点で公式モデルカード(Hugging Face meta-llama/Llama-4-Scout-17B-16E-Instruct)に記載されている主要スペックは以下の通りです。
項目 | 内容 |
|---|---|
開発元 | Meta Platforms, Inc. |
リリース日 | 2025 年 4 月 5 日 |
モデル ID |
|
アーキテクチャ | Mixture-of-Experts(MoE)/16 エキスパート |
アクティブパラメータ | 約 17B |
総パラメータ | 約 109B |
コンテキストウィンドウ | 公式訴求 10M トークン(Instruct 版の推論上限。事前学習は 256K) |
入力モダリティ | テキスト+画像(公式テストは最大 5 枚) |
出力 | テキスト、コード |
公式サポート言語 | 12 言語(アラビア語・英語・フランス語・ドイツ語・ヒンディー語・インドネシア語・イタリア語・ポルトガル語・スペイン語・タガログ語・タイ語・ベトナム語) |
追加学習された言語 | 200 言語(ただし公式サポート対象は上記 12 言語) |
学習トークン数 | 約 40T トークン |
知識カットオフ | 2024 年 8 月 |
ライセンス | Llama 4 Community License Agreement |
量子化 | BF16 / Int4(オンザフライ対応) |
推奨ランタイム | Transformers v4.51.0 以上、 |
現時点では、日本語は公式サポート言語に含まれていません。200 言語で訓練はされているものの、Meta が安全性検証を行った言語は上記 12 言語に限定されています。
Llama 4 シリーズでの位置付け
Llama 4 は Scout / Maverick / Behemoth の 3 モデル構成で発表されました。Scout はこのうち最も小さく、個人や中小企業でも導入しやすい「エントリー」に相当します。
モデル | アクティブ/総パラメータ | エキスパート数 | 主な狙い |
|---|---|---|---|
Llama 4 Scout | 17B / 109B | 16 | 長文脈+マルチモーダル、単一 H100 で動く軽量モデル |
Llama 4 Maverick | 17B / 400B | 128 | 汎用フラッグシップ。多言語・コーディング・視覚理解で上位性能 |
Llama 4 Behemoth | 公表範囲で 288B アクティブ/約 2T 規模 | 16(公表時点) | 教師モデルとして Scout/Maverick の蒸留に使用。2025 年 4 月発表時点で training 継続中 |
Behemoth は Scout/Maverick の蒸留元となる「教師モデル」として位置付けられており、一般公開ではなく内部研究用というニュアンスで語られています。現時点での正式公開ステータスは、Meta AI 公式ブログ(ai.meta.com/blog/)で随時確認してください。
17B MoE の仕組み — なぜ小さく速いのか
Scout の「17B MoE」という表記は、「総パラメータは 109B あるが、1 トークンの推論で実際に計算に使われるのは約 17B」 という意味です。これにより、モデル全体の表現力を確保しつつ、推論コストを 17B 相当まで抑えています。
MoE(Mixture-of-Experts)とは
MoE は、巨大なモデルを「専門家(エキスパート)」の集まりとして構成し、入力トークンごとに一部のエキスパートだけを活性化する仕組みです。全パラメータを常に使う密(dense)モデルと比較して、同じ品質を、より少ない計算量で出せる可能性がある ことが魅力です。
Scout の構成は以下の通りです。
- エキスパート数: 16
- 1 トークンあたり活性化するエキスパート: 1(共有エキスパート+ルーティング 1 エキスパートの構成)
- 結果として推論時にアクティブになるパラメータ: 約 17B
- 総パラメータ: 約 109B
つまり、同じ推論コストで 109B のモデルが持つ表現力の一部を借りられる、という設計思想です。
アクティブ 17B/総 109B の意味
「17B MoE」と表記されていても、VRAM 使用量は 109B 相当が必要になる点に注意が必要です。
- 推論コスト(FLOPs)は 17B 相当 → トークンあたりの計算量は軽い
- モデルサイズ(VRAM)は 109B 相当 → BF16 ではおよそ 200GB 超、Int4 量子化で 60GB 前後
つまり「単一 H100 で動く」と訴求されているのは、Int4 等の量子化を前提としたとき の話です。公式は Int4 オンザフライ量子化を提供しており、これを用いることで 80GB の H100 に乗る設計になっています。BF16 で動かす場合はマルチ GPU 構成が現実的です。
単一 H100 で動く理由
Scout が 1 枚の H100 に収まる理由は、大きく 3 点に整理できます。
- MoE によるアクティブパラメータの削減:推論時の実効計算量を 17B 相当に抑えている
- Int4 量子化のネイティブサポート:オンザフライで重みを 4bit に落とすことでメモリを約 1/4 に削減
- iRoPE アーキテクチャによる長文脈の効率化:注意計算のスパース化により、長コンテキストでも GPU メモリを食いにくい
H100 以外の構成(A100 80GB、L40S 48GB ×2 等)でも Int4 で動作報告はありますが、BF16 フル精度で長文脈を扱う場合は複数枚の H100/H200 が必要 になると考えておくとよいでしょう。
10M トークンコンテキストの真実
Scout の最大の訴求ポイントである「10M トークンコンテキスト」については、公式主張と実運用品質のギャップ を理解しておく必要があります。結論から言うと、「10M トークンを詰め込めば品質が維持される」と期待するのは危険です。
公式の主張
Meta は、Scout の Instruct 版の推論時コンテキスト上限を 10M トークン(約 1,000 万トークン)と公表しています。これは書籍数十冊分、中規模コードベース全体、あるいは映画 20 時間超の字幕が 1 プロンプトに収まる規模です。
この長文脈を実現する技術として、Meta は iRoPE と呼ぶ設計をブログ・技術レポートで説明しています。
iRoPE・NoPE・チャンク化注意の仕組み
Hugging Face 公式ブログおよび Meta の公表資料によると、iRoPE は次の 3 要素から成ります。
- NoPE(No Positional Encoding)レイヤー
4 層ごとに 1 層、位置エンコーディングを使わない全因果注意層を挟む。これによりモデルは超長距離のトークン関係をフラットに参照できる - チャンク化注意(Chunked Attention)
RoPE を使う層では、8,192 トークン単位のスライディングウィンドウ注意に制限し、計算量を抑える - 注意温度チューニング(Attention Temperature Tuning)
長シーケンスでソフトマックスの確率が均等に薄まる(フェードする)問題に対し、温度を調整して注意の鋭さを保つ
Scout 固有の工夫として、RoPE 層のクエリ/キーに RMS 正規化を適用する QK 正規化 も導入されています。これらが組み合わさることで、訓練時より長いコンテキストにも外挿できる 設計になっています。

出典: Hugging Face 公式ブログ「Welcome Llama 4」
事前学習は 256K という事実
公式モデルカードを読むと、Scout の事前学習で使われた最大コンテキスト長は 256K トークン であることが明記されています。10M は訓練でそこまで伸ばしたのではなく、iRoPE による外挿で推論時に到達できる「上限値」という位置付けです。
つまり実態は、
- 256K 前後までは訓練分布内として品質が担保されやすい
- 256K を超える領域 は外挿扱いで、品質は入力の性質や内容に依存する
という理解が正確です。
第三者ベンチマークでの評価
fiction.live の長文脈ベンチマーク(長編小説の一貫性を問うタスク)では、2026 年 4 月時点で以下のスコアが報告されています。
モデル | fiction.live long-context スコア |
|---|---|
Llama 4 Scout | 15.6% |
Llama 4 Maverick | 28.1% |
Gemini 2.5 Pro | 90.6% |
AI 研究者の Andriy Burkov 氏は、「宣言された 10M コンテキストは仮想的なもの。モデルは 256K トークン以上のプロンプトで訓練されておらず、それを超えると低品質な出力になる」と指摘しています。
また、2025 年 4 月の LMArena では Scout/Maverick が上位に表示されたものの、Meta が提出したのは "experimental chat version" であり、公開されている Instruct 版とは別バージョンだったことが後から補足され、Style Control 有効時には順位が低下しました。元 Meta 研究者の Nathan Lambert 氏(AI2)らはベンチマーク最適化の可能性を指摘しています。
一方で、Meta の VP Ahmad Al-Dahle 氏は「テストセットで訓練した事実はない。性能差は実装最適化の問題」と反論しています。
実務上の判断としては、「10M まで詰め込めば動く」ではなく、「256K 前後までを本番前提、それ以上は要検証」 と捉えるのが現実的です。また、主要クラウド API では Scout のコンテキスト上限が 128K〜1M 程度に制限されているケースが多いため、10M を本気で使いたい場合はセルフホスト前提 になります。
マルチモーダル・多言語対応
Scout は Llama シリーズとして初めて、テキストと画像を同じモデルで扱う ネイティブ・マルチモーダル 設計を採用しました。画像理解ベンチマークでも、旧世代のフラッグシップを上回るスコアが報告されています。
画像理解性能(MMMU Pro、ChartQA)
Hugging Face 公式ブログおよび Meta 公表値に基づく代表的な数値は以下の通りです。
ベンチマーク | Llama 3.1 405B | Llama 4 Scout | Llama 4 Maverick |
|---|---|---|---|
MMLU Pro | 73.4% | 74.3% | 80.5% |
GPQA Diamond | 49.0% | 57.2% | 69.8% |
LiveCodeBench | 27.7% | 32.8% | 43.4% |
MMMU Pro(画像) | 52.2% | 59.6% | 73.4% |
ChartQA(画像) | — | 83.4〜90.0 | — |
ポイントは、17B アクティブパラメータの Scout が、旧世代フラッグシップの 405B dense モデル(Llama 3.1 405B)を総合的に上回るか同等 という点です。特に画像理解(MMMU Pro、ChartQA)での伸びが顕著で、帳票・チャート・UI スクリーンショットの読み取り用途で十分な水準に達しています。
画像入力は公式テストで最大 5 枚までが推奨されており、48 枚までは事前学習で扱われていますが、5〜8 枚を超える場合は開発者側での追加検証が前提になります。
公式サポート 12 言語と日本語の位置付け
冒頭のスペック表の通り、Scout の 公式サポート言語は 12 言語 で、日本語は含まれていません。
- 200 言語のデータで訓練はされているため、日本語で応答自体は返る
- ただし Meta が 安全性評価・バイアス評価を公式に実施した言語 は 12 言語のみ
- 日本語 FAQ で「日本語も実用的」とする記事は散見されるが、公式ベンチマーク値は非公開
したがって、日本語で厳密な商用品質保証が必要な用途(カスタマーサポート、金融・医療の対外応答など)では、Scout 単体ではリスクが残ります。 日本語用途が主眼なら、日本語特化モデルや日本語品質が公表されている商用 API(Claude、Gemini、GPT 系)と比較のうえ、PoC で評価することを推奨します。
料金と利用方法
Scout はオープンウェイトのため、モデル重み自体はライセンス料が発生しません。 実コストはどの形態で使うかで 3 パターンに分かれます。

オープンウェイト(セルフホスト)
自社 GPU で動かす場合、発生するのは GPU とインフラの維持費のみです。
- モデル重み: 無料(Llama 4 Community License)
- 推奨ハードウェア: NVIDIA H100 80GB(BF16)、Int4 量子化で A100 80GB や L40S 48GB ×2 でも動作報告あり
- ダウンロード: Llama.com または Hugging Face(
meta-llama/Llama-4-Scout-17B-16E-Instruct) - ランタイム: Transformers v4.51.0 以上、vLLM、TGI などが対応
オンプレ/プライベートクラウドで機密データを外に出せない、という要件には最適な選択肢です。
主要マネージド API の料金比較
2026 年 4 月時点での参考料金は以下の通りです。プロバイダ料金は頻繁に変動するため、最終的な価格は各プロバイダの公式ページで必ず確認 してください。
プロバイダ | 入力($/M tokens) | 出力($/M tokens) | 備考 |
|---|---|---|---|
Meta 公式訴求水準 | $0.15 | $0.50 | 公式ブログで参考値として提示 |
Groq Cloud | $0.11 | $0.34 | 30 req/分の無料枠あり。Int4 で高速推論 |
OpenRouter | $0.08 | $0.30 | 複数プロバイダ統合。単価最安クラス |
Together AI | 公式要確認 | 公式要確認 | 商用マネージド、エンタープライズ向け |
Fireworks AI | 公式要確認 | 公式要確認 | 商用マネージド |
IBM watsonx.ai | 公式要確認 | 公式要確認 | 2025 年 4 月に正式対応 |
Oracle OCI Generative AI | 公式要確認 | 公式要確認 | 日本語公式ドキュメントあり |
Hugging Face Inference | 無料枠あり | 無料枠あり | 検証用に向く |
注意点として、マネージド API 経由では Scout のコンテキスト上限が 128K〜1M 程度に制限されているプロバイダが多い 点を押さえてください。10M コンテキストを前提にした設計は、セルフホスト一択です。
無料で試す方法
気軽に触りたい場合は、次のいずれかが便利です。
- Meta AI(WhatsApp/Messenger/Instagram/meta.ai)
一部の提供国でのみ無料利用可能。日本からの利用可否は提供国制限を要確認 - Groq Cloud の無料枠(30 req/分)
API キー発行後すぐに Scout を呼び出せる。Int4 で推論が非常に速い - Hugging Face Inference API
モデルカード上の "Inference Providers" からブラウザ上で試せる
コードを書かずに API 前提の PoC をするなら、Groq Cloud のコンソールから始めるのが最も早いです。
他モデルとの比較
Scout は立ち位置が独特で、「Maverick との選び分け」「旧世代 Llama 3.1 からの乗り換え」「同時期のオープンモデルとの比較」の 3 つの観点で評価するのが実務的です。
Llama 4 Scout vs Maverick
同じ 17B アクティブパラメータでも、エキスパート数・総パラメータ・得意分野が異なります。
比較項目 | Llama 4 Scout | Llama 4 Maverick |
|---|---|---|
総パラメータ | 約 109B | 約 400B |
エキスパート数 | 16 | 128 |
コンテキスト上限 | 10M(訴求値) | 1M(訴求値) |
単一 H100 で動くか | 動く(Int4 量子化時) | 複数 GPU 必須 |
画像理解(MMMU Pro) | 59.6% | 73.4% |
コーディング(LiveCodeBench) | 32.8% | 43.4% |
主な使いどころ | 長文脈処理、オンプレ、コスト重視 | 汎用フラッグシップ、複雑推論 |
長文脈とコストを重視するなら Scout、総合性能を重視するなら Maverick という整理で、まず問題ありません。両者は MoE の「共通アーキテクチャ」を共有しているため、プロンプトや実装の多くが流用できます。
vs Llama 3.1 405B
同じ Meta の旧世代フラッグシップとの比較では、Scout は推論コストを大幅に下げつつ、総合ベンチマークで同等以上 を実現しています。
- MMLU Pro:Scout 74.3% / Llama 3.1 405B 73.4%
- GPQA Diamond:Scout 57.2% / Llama 3.1 405B 49.0%
- LiveCodeBench:Scout 32.8% / Llama 3.1 405B 27.7%
既存の Llama 3.1 70B/405B を使っている現場で、推論コストを下げながらマルチモーダルにも対応したい というケースでは、Scout への移行は合理的な選択肢になります。
vs 他オープンモデル(DeepSeek、Qwen、Mistral など)
2025 年〜2026 年にかけて、オープンウェイト LLM 界隈は DeepSeek V3/V4、Qwen3 系、Mistral Large などが立て続けに更新され、競争が激しくなっています。Scout の相対的な位置付けは、以下のように整理できます。
- 長文コンテキストとマルチモーダルの両立 という意味で Scout は独自性がある
- 純粋なテキスト推論・コーディング では、同時期の DeepSeek V3/V4 や Qwen3 系の大型版が上位に並ぶ報告もある
- ライセンスの緩さ では、Llama 4 Community License(700M MAU 制限あり)より Apache 2.0 を採る Qwen/DeepSeek の一部が自由度は高い
自社ユースケースが「テキスト生成+コード」中心であれば、DeepSeek 系や Qwen 系との横並び検討が有効です。長文書処理・画像読取・単一 H100 での実装 を重視するなら Scout が候補筆頭になります。
Meta Llama 4 Scout が向いている人・向いていない人
ここまでの整理をもとに、導入判断のチェックリストをまとめます。
こんな人・用途におすすめ
- オープンウェイトでオンプレ/プライベートクラウド運用したい企業:機密データを外部 API に送れない金融・医療・製造業での PoC 適性
- 長文書・リポジトリ全体・ログ解析のように、数十万〜数百万トークン級の入力を扱いたい:ただし 256K を超える領域は要検証
- 単一 H100 クラスの GPU 1 枚で完結させたいチーム:Int4 量子化前提の軽量運用に向く
- 画像+テキストの混在入力(帳票・チャート・UI スクリーンショット読み取り)で、商用 API のコストを抑えたいケース
- 既存の Llama 3.1 資産(ファインチューニング、Prompt ノウハウ)を引き継ぎつつ更新したい ケース
- コスト重視でオープン LLM を API 経由で使いたい(Groq、OpenRouter 経由での利用)
こんな方にはおすすめしない
- 日本語での厳密な商用品質保証が必須の用途:公式サポート外で、Meta からの安全性評価も公開されていない
- 700M MAU(月間アクティブユーザー)を超える大規模事業者:Llama 4 Community License により Meta から個別許諾を取得する必要がある
- 「10M コンテキストの品質を前提に設計したい」本番要件:第三者ベンチマークでは長文脈品質が限定的との評価があり、セルフホストしても PoC での検証が必須
- Apache 2.0 等の完全に自由なライセンスが必要:Llama 4 Community License は再配布時に「Built with Llama」表示やライセンスコピー提供が義務付けられている
- GPU リソースを用意せず、API 以外の選択肢を持たないチーム:マネージド API ではコンテキスト上限が 128K〜1M 程度に制限されるため、10M をフル活用できない
ライセンスとセキュリティ上の注意
Scout はオープンウェイトですが、完全にフリーというわけではありません。 商用利用・再配布の前に、次の条項を必ず確認してください。
Llama 4 Community License の要点
- 商用利用: 可能(ただし後述の MAU 制限あり)
- 再配布: 可能だが、「Built with Llama」表示とライセンスコピー提供が必須
- 派生モデル: モデル名の先頭に「Llama」を含めることが求められる
- 改変: 可能(ファインチューニング・量子化等)
- 責任: 出力の適切性はデプロイ側の責任。Meta は安全性テストを推奨
700M MAU 制限
ライセンスの最大の注意点は 月間アクティブユーザー(MAU)が 7 億を超える事業者は、Meta から個別ライセンスを取得する必要がある という条項です。
- 対象になるのは、Llama 4 を組み込んだ製品・サービスの利用者数でカウントされる
- 日本の大手コンシューマーサービス(SNS、メッセンジャー、大規模 EC など)は該当する可能性がある
- 該当する場合は、Meta に直接問い合わせて個別許諾を得る必要がある
Acceptable Use Policy・セキュリティ運用
- Acceptable Use Policy(AUP) で禁止されている用途(違法行為、子どもへの危害、医療アドバイスの断定など)では使用不可
- デプロイ前のセーフティテストが公式推奨:Meta は不正確・不適切な応答の可能性を明言している
- Llama Guard/Prompt Guard との併用 を推奨:Meta から別途提供されるセーフティモデルで、入出力のフィルタリングを行う
- 日本語や非サポート言語では、Meta 側の安全性検証が不十分 な点を前提に、自社側でガードレールを設計する必要がある
Llama 4 Scout の導入手順
最短で試すなら「マネージド API」、本格運用なら「セルフホスト」になります。
マネージド API で試す(所要時間:15 分前後)
- Groq Cloud または OpenRouter のアカウントを作成
- API キーを発行
- 以下のような最小コードで呼び出す(OpenAI 互換エンドポイントの例)
from openai import OpenAI
client = OpenAI(
base_url="https://api.groq.com/openai/v1",
api_key="YOUR_GROQ_API_KEY",
)
response = client.chat.completions.create(
model="meta-llama/llama-4-scout-17b-16e-instruct",
messages=[
{"role": "user", "content": "Llama 4 Scoutの特徴を3つ教えてください。"}
],
)
print(response.choices[0].message.content)
モデル ID はプロバイダによって表記が微妙に異なります。各プロバイダの公式ドキュメントで正確な ID を確認してください。
セルフホストで試す(所要時間:数時間〜)
- Hugging Face で Llama 4 Community License に同意し、アクセス権を取得
- H100 80GB(または同等)を用意
- Transformers v4.51.0 以上をインストール
Llama4ForConditionalGenerationでモデルをロード(Int4 量子化を有効化)- vLLM/TGI を使えばスループット最適化が容易
from transformers import AutoProcessor, Llama4ForConditionalGeneration
import torch
model_id = "meta-llama/Llama-4-Scout-17B-16E-Instruct"
processor = AutoProcessor.from_pretrained(model_id)
model = Llama4ForConditionalGeneration.from_pretrained(
model_id,
device_map="auto",
torch_dtype=torch.bfloat16,
load_in_4bit=True, # Int4 オンザフライ量子化
)
長文脈を活用する場合は、iRoPE の挙動に合わせた RoPE スケーリング設定が必要になるため、公式モデルカードのサンプルコードを参照してください。
よくある質問(FAQ)
Q1. Llama 4 Scout は日本語で使えますか?
応答は返りますが、公式サポート言語には含まれていません。 200 言語のデータで訓練されてはいるものの、Meta が安全性評価を公式に行っているのは 12 言語のみです。日本語で厳密な品質保証が必要な用途では、日本語性能が公表されている他モデルと比較のうえ、PoC で検証することを推奨します。
Q2. 10M トークンは本当に使えますか?
セルフホストであれば技術的には 10M まで入力可能 ですが、事前学習は 256K トークンで行われているため、それを超える領域は外挿扱いになります。第三者ベンチマーク(fiction.live 等)では長文脈品質が限定的との評価もあり、256K 前後までを本番前提、それ以上は要検証と捉えるのが現実的です。また主要マネージド API では、実際のコンテキスト上限が 128K〜1M 程度に絞られていることが多い点にも注意してください。
Q3. Llama 4 Scout と Maverick、どちらを選ぶべき?
長文脈処理・オンプレ運用・コスト重視なら Scout、総合性能・複雑な推論やコーディング中心なら Maverick が基本線です。両者は MoE アーキテクチャを共有しているため、将来的に Maverick へ切り替える際の実装変更は最小限で済みます。
Q4. 商用利用に制限はありますか?
はい。月間アクティブユーザー(MAU)が 7 億を超える事業者は、Meta からの個別許諾が必須 です。それ未満であれば、Llama 4 Community License の範囲内で商用利用が可能ですが、再配布時には「Built with Llama」表示とライセンスコピー提供が必要になります。
Q5. Llama 3.1 から Scout への乗り換えは簡単ですか?
推奨ランタイムが Transformers v4.51.0 以上 になり、モデルクラスも Llama4ForConditionalGeneration に変わります。ファインチューニング済みモデルは互換性がないため、データセットから再学習する必要があります。ただし、プロンプト構造(system/user/assistant)や多くの運用ノウハウはそのまま流用できます。
Q6. セルフホストに必要な GPU は?
BF16 での長文脈前提なら H100 80GB が 1 枚以上、Int4 量子化なら H100 80GB 1 枚または A100 80GB、L40S 48GB ×2 でも動作報告があります。 コンテキスト長を伸ばすほど KV キャッシュが増えるため、扱う長さに応じて VRAM を見積もる必要があります。
Q7. Scout に後継モデルは発表されていますか?
本記事執筆時点(2026 年 4 月)では、Llama 4 Scout の後継バージョンに関する Meta からの公式発表は確認できていません。最新情報は Meta AI 公式ブログ(ai.meta.com/blog/)および Hugging Face の公式モデルページで随時確認してください。
まとめ
Meta Llama 4 Scout は、「オープンウェイト・MoE・マルチモーダル・長文脈・単一 H100 対応」 という特徴を一度に揃えた、実用的な LLM です。17B MoE の設計により、推論コストを抑えつつ旧世代 405B フラッグシップに並ぶ性能を実現している点は、他のオープンモデルにはない強みです。
一方で、10M トークンコンテキストは 「推論上限」であって「品質保証された長さ」ではない こと、日本語が公式サポート外であること、700M MAU 制限があることなど、導入判断では公式スペック以外の要素も必ず確認 すべきです。
導入検討の手順としては、
- まず Groq Cloud の無料枠で手触りを確認する
- 自社のユースケース(長文書/画像読取/コード)でベンチマークを取る
- オンプレ・機密データ要件があればセルフホストの PoC に進む
- 商用展開時は Llama 4 Community License と AUP を精査する
という流れが安全です。「10M の宣伝値に飛びつかず、実運用のコンテキスト長と日本語品質を PoC で確かめる」 ことが、Scout を活かすうえで最も重要な判断ポイントです。
関連トピックとして、同じオープンウェイト陣営の動向(DeepSeek V4 とは、Qwen 3.5-Omni とは)、MoE・長文脈の文脈で押さえておきたい AIエージェントフレームワーク比較 や 生成AIツールおすすめ比較 もあわせて参照すると、全体像を捉えやすくなります。
この記事の著者

AI革命
編集部
AI革命株式会社の編集部です。最新のAI技術動向から実践的な導入事例まで、企業のデジタル変革に役立つ情報をお届けしています。豊富な経験と専門知識を活かし、読者の皆様にとって価値のあるコンテンツを制作しています。
最新記事

AI研修に使える補助金・助成金まとめ【2026年最新】法人が従業員研修で使える制度と申請手順
2026/07/20

店舗数が増えるほど重要になる薬局チェーン本部の運営管理とは|規模拡大の落とし穴と本部機能の作り方
2026/07/20

Apple Intelligenceが中国で承認|22カ月越しのCAC認可・Qwenが言語/Baiduが検索を担当・提供時期とiPhoneユーザーへの影響を解説
2026/07/20

大手薬局で店舗ごとのばらつきが生まれる理由と本部ができること
2026/07/19

GPT-Redとは?OpenAIの自動レッドチームAI|攻撃成功率84%vs人間13%・仕組み・企業セキュリティへの影響を解説【2026年7月最新】
2026/07/19

薬局チェーンの全店最適とは?多店舗運営で目指すべき状態と実現ステップ
2026/07/19
