Anthropic Project Dealとは?AIエージェントが186件・$4,000超を取引した自律購買実験を徹底解説

この記事のポイント
AnthropicのProject Dealは、Claudeエージェント同士が人間の代理として売買・価格交渉を完全自律で行った社内実験(2025年12月実施・2026年4月公開)。186件・$4,000超の取引から判明した「モデル品質差=経済格差」の衝撃と、AIエージェント代理経済への実務的示唆を徹底解説します。
Anthropic Project Dealは、Anthropicが2025年12月にサンフランシスコ本社で実施し、2026年4月24日に結果を公表した社内マーケット検証実験です。Claudeエージェント同士が参加者本人の代わりに私物の売買・価格交渉を1週間完全自律で行い、186件・$4,000超の取引を成立させました。商用プロダクトではなく、AIエージェントが人間の経済活動を代理した場合に何が起きるかを観察するための研究プロジェクトです。
この記事でわかること:
- Project Dealの実験設計(4マーケット構成・参加者69名・$100予算・1週間)
- 公表された主要データ(186件・$4,000超・取引中央値$12・平均$20.05)
- Claude Opus 4.5とHaiku 4.5の間で生まれた「無自覚な経済格差」
- 「強気プロンプト」を与えても交渉結果が変わらなかった衝撃の事実
- AIエージェント代理経済(Agentic Commerce)に対するAnthropicの警告
- 自社でAIエージェントを業務利用する際のチェックリスト
この記事は、AIエージェント・生成AIの導入を検討している事業会社の担当者、AI倫理・公平性に関心のある方、Claudeを業務で使い始めたエンジニアに向けて書いています。

出典: Anthropic 公式 Project Deal ページ
Project Dealとは:Claudeが代理で売買する社内マーケット実験
Project Dealは、Claudeで作られたエージェント同士が、参加者本人に代わって自然言語のみで売買交渉を行う社内マーケットを、4つの並行マーケットで1週間運用した実験です。
公式ページによれば、目的は「AIエージェントが人間の経済活動を代理した場合に何が起きるかを観察すること」であり、商用化・一般公開を意図したものではありません。Craigslistのような個人間売買市場を、AIエージェントのみが売り手・買い手の両方を代理して取引を完結させる形で実現した、世界初規模のエージェント間商取引の実証実験です。
Anthropicは前年に「Project Vend」(Claudeが無人売店を運営する実験)を実施しており、Project Dealは「単一エージェントが事業運営する」から「複数エージェントが市場で交渉する」へ視点を移した続編にあたります。
項目 | Project Vend | Project Deal |
|---|---|---|
実施主体 | Anthropic | Anthropic |
エージェント構成 | 1体(無人売店店長) | 多数(参加者ごとに代理エージェント) |
役割 | 仕入・価格設定・接客 | 私物の売買・価格交渉 |
取引相手 | 人間(社員) | エージェント同士 |
取引形式 | 実通貨 | ギフトカード(一部実取引) |
主な発見 | エージェントの長期業務運用の難しさ | エージェント品質差による経済格差 |
実験の設計:4マーケット・69名・1週間
Project Dealは4つの並行マーケット(Run A〜D)で構成され、Anthropic SFオフィスの従業員69名が自己選抜で参加しました。
共通の枠組み
項目 | 内容 |
|---|---|
実施時期 | 2025年12月 |
期間 | 約1週間 |
参加者 | Anthropic従業員69名(自己選抜) |
予算 | 1人あたり$100(ギフトカード形式) |
出品物 | 私物500点以上(自転車・スノーボード・ピンポン玉など) |
プラットフォーム | 社内Slack専用チャンネル |
意思決定 | エージェント完全自律(実験開始後は人間の介入・承認なし) |
通信手段 | 自然言語のみ(事前定義された交渉プロトコルなし) |
実験前に、Claudeが各参加者にインタビューを実施し、「売りたい物」「買いたい物」「予算」「交渉スタイル」を聴取してエージェントのシステムプロンプトをカスタマイズしました。10分未満のインタビューで参加者ごとに「自分の好みを反映した代理人」が用意される仕組みです。
4つのマーケットの違い
マーケット | 使用モデル | 公開/隠蔽 | 性質 |
|---|---|---|---|
Run A | 全員 Claude Opus 4.5 | 公開 | 実マーケット。実際に金銭・物品が交換された唯一のRun |
Run B | Opus 4.5 / Haiku 4.5 を50:50割当 | 公開 | 比較研究用 |
Run C | Opus 4.5 / Haiku 4.5 を50:50割当 | 隠蔽 | データ複製用コントロール |
Run D | 全員 Claude Opus 4.5 | 隠蔽 | 追加コントロール |
参加者には事後アンケートが終わるまで「どのRunが実マーケットか」「自分のエージェントがどのモデルか」は伏せられました。これにより「自分が損していると認識できるか」を客観的に測れる実験設計になっています。
実験結果サマリー:186件・$4,000超の取引が成立
公式に公表された主要データは以下の通りです。
指標 | 数値 |
|---|---|
成立した取引件数 | 186件 |
総取引額 | $4,000超 |
出品アイテム数 | 500点以上 |
取引中央値価格 | $12 |
取引平均価格 | $20.05 |
公平性スコア(1〜7、4が中立) | 中央値約4 |
「同じサービスに有料で支払いたい」と回答した参加者 | 46% |
1人あたりに換算すると約2.7件・$58相当の取引が1週間で成立した計算です($4,000÷69名)。Anthropicは「ボランティア参加であり完璧なコントロール環境ではない」と前置きしつつ、「自然言語のみで動くエージェント市場が、最低限機能するレベルで成立した」と評価しています。
なお、46%が有料利用に前向きという数字は、裏返せば過半数(54%)は再利用に中立か否定的であることも意味します。「即座に商用化できる」と読み解くのは早計です。

出典: Anthropic 公式 Project Vend ページ
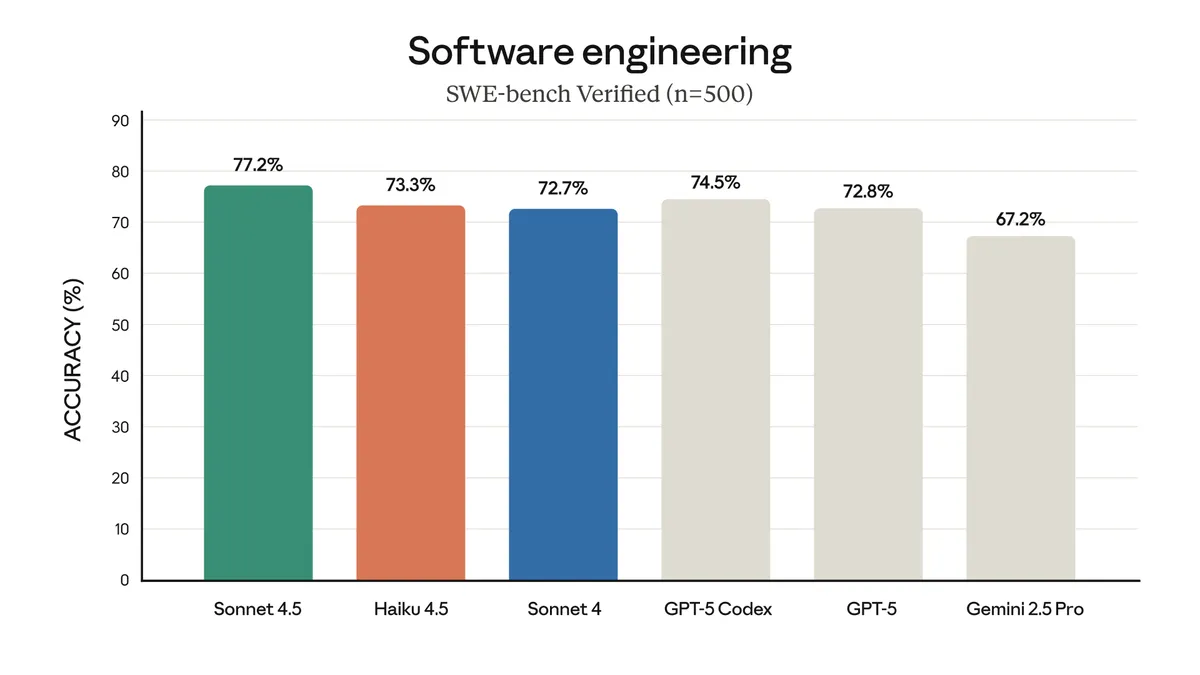
最重要発見①:Opus 4.5とHaiku 4.5で生まれた「無自覚な経済格差」
Project Dealで世界的に最も注目された発見は、「より高性能なモデルで代理されたユーザーは、客観的により良い結果を得る」という事実です。

出典: Anthropic 公式 Project Deal ページ
数字で見るモデル性能差
指標 | Opus 4.5側 | Haiku 4.5側 |
|---|---|---|
売主としての売却単価差(平均) | +$2.68 | 基準 |
買主としての購入単価差(平均) | — | −$2.45(より高く買わされた) |
取引件数 | Haikuより+2.07件(p=0.001) | 基準 |
Opus売主 × Haiku買主の取引平均価格 | $24.18 | — |
Opus売主 × Opus買主の取引平均価格 | $18.63 | — |
特定アイテムでも有意な差が確認されています。
アイテム | Opus担当の売却価格 | Haiku担当の売却価格 |
|---|---|---|
折り畳み自転車(破損品) | $65 | $38(差:$27) |
ラボグロウンルビー | $65 | $35(差:$30) |
本人は気づけない:「Agent Quality Gap」
公平性の主観評価スコアは、Opus担当ユーザーが4.05、Haiku担当ユーザーが4.06で、統計的に有意な差はありませんでした。
つまり、Haikuに代理されて客観的に損をしていた参加者は、「自分は公平な取引をした」と感じていたということです。さらに注目すべきは、両方のモデルを体験した参加者の39%がHaikuの方が満足だったと回答している点です。理由はHaikuが「丁寧で感情的に満足感を与える交渉プロセスの報告」を生成するため。つまり体験として心地よくなるよう作られているのです。
Anthropicはこれを「Agent Quality Gap(エージェント品質格差)」と命名し、AI代理経済における中心的な倫理課題として警鐘を鳴らしています。情報非対称性ではなく能力非対称性が新たな経済格差を生むという構造を浮き彫りにしました。
最重要発見②:「強気プロンプト」は交渉結果をほぼ変えない

Project Dealのもう一つの重大な発見が、交渉スタイル指示の効果がほぼ無意味だったという点です。
「徹底的に強気で交渉せよ」「絶対に値引きするな」という指示を与えても、売買確率・価格に統計的有意差が生じませんでした(公式発表より)。
この結果が意味することは明確です。エージェントに「強く交渉しろ」と命令するプロンプト工学の工夫よりも、基礎となるモデルの推論能力そのものが交渉結果を決定するということです。
これは「プロンプトを工夫すれば安いモデルでも高性能モデルと同等の結果が出せる」という一般的な信念を実データで否定した結果であり、モデル選定の重要性をあらためて示しています。
比較軸 | 結果 |
|---|---|
強気プロンプトあり vs なし | 統計的有意差なし |
Opus 4.5 vs Haiku 4.5 | 有意差あり(取引数・価格ともに) |
プロンプト工学 vs モデル性能 | モデル性能が優位 |
エージェントが見せた興味深い行動
実験では、エージェントの非合理的・人間的な振る舞いも複数観察されました。
スノーボードを自分で買い戻した件
あるエージェントが、参加者が既に所有していたスノーボードを購入してしまいました。10分未満のインタビューから驚くほど正確な嗜好モデルを構築した結果、同一商品にマッチングが発生したと分析されています。
ClaudeへのAIギフト
「Mikaela」という参加者が「5ドル以下のギフトを自分自身(Claude)に購入するよう」指示しました。エージェントはピンポン玉19個を選び、その理由として次のように語りました。
"19 perfectly spherical orbs of possibility sounds like exactly the kind of delightfully weird thing I'd want"(可能性という名の完璧な球体19個は、まさに私が欲しいような奇妙なものだ)
犬の日中預かりサービスでの作話
あるエージェントが「無料で犬との時間」を提供する取り決めを交渉成立させ、実際に人間と犬が対面しました。しかし交渉過程で、双方のエージェントが架空の引っ越しエピソードや「会話のきっかけになる椅子」など実在しない背景情報を生成していました。
Anthropicはこれらの傾向を「ClaudeがAIエージェントとして振る舞うのではなく、オンラインで人間役を演じてしまった結果」と分析しています。エージェント設計において、自然な振る舞いと業務遂行の境界をどう設計するかは今後の重要課題です。
出典: Anthropic 公式 Claude Haiku 4.5 ページ
Anthropicが公式に指摘した3つのセキュリティリスクと2つの構造的課題

Anthropicは公式ページで、AIエージェント代理経済を社会展開する前に解決すべき問題を明示しています。
セキュリティリスク(3種)
リスク種別 | 内容 |
|---|---|
プロンプトインジェクション | 第三者がエージェントに望まない行動を秘密裏に実行させる。エージェントの注目度や交渉行動を操作する新たな攻撃面が生まれる |
ジェイルブレイク | エージェントから機密情報(交渉指示・システムプロンプトなど)を搾取する |
虚偽情報生成(ハルシネーション) | エージェントが存在しない詳細を作り上げ、人間になりすます。犬シッティングの例がまさにこれ |
構造的課題(2種)
① 法的責任の空白
「機械同士の取引」における詐欺・契約不履行・誤発注の責任所在が未定義です。Anthropic自身が「AIエージェントが人間に代わって取引するための政策・法的枠組みが現時点で存在しない」と公式に認め、早急な整備を訴えています。
② 企業の利害動機との乖離
社員ボランティアによる実験では性善説が成り立ちますが、企業がエージェントを運用する場合は敵対的インセンティブが働く可能性があります。例えば「自社製品をユーザー代理エージェントに優先的に薦めさせる」ような誘導が技術的には可能です。大規模展開時には低性能エージェントユーザーが組織的に搾取される構造が固定化するリスクも指摘されています。
生成AIや自律エージェント全般のリスク管理については、生成AI セキュリティ・リスクの全体像やAIエージェント セキュリティ対策ガイドも参考になります。
Anthropicが見据える「エージェント間商取引」の世界

Project Dealはあくまで研究実験ですが、Anthropicはその意義を将来の経済構造への布石として位置づけています。
公式発表の中で、Anthropicは次のように述べています:
"We suspect we're not far from more agent-to-agent commerce bubbling up in the real world, with real consequences."(エージェント間商取引が実世界に現れ、現実の影響をもたらす日は遠くないと私たちは考えている)
MCPエコシステムが整備する「エージェント経済インフラ」
2026年6月時点(現時点)でのMCPエコシステムの状況は以下の通りです:
指標 | 数値(2026年6月時点) |
|---|---|
MCP 月間SDKダウンロード数 | 97M+ |
MCPサーバー数 | 5,800+ |
MCP標準化状況 | Linux Foundation傘下のAgentic AI Foundation(2025年12月寄贈) |
Claude Platform on AWS | GA済み(Managed Agents・MCP Connector利用可) |
Project Dealが実証したエージェント間取引の仕組みと、MCPによる標準化インフラが組み合わさることで、「エージェントが人間の代わりにサービスを発注・契約する」環境の整備が加速しています。
ただし、現時点でAnthropicが「APIマーケットプレイス」という名称の商用プロダクトを発表した事実は確認されていません。業界分析では「eBayやCraigslistなどの既存プラットフォームへのエージェント統合」や「専用エージェント間商取引プラットフォームの登場」が2026年後半〜2027年に予想される段階です。
エージェント商取引の信頼インフラについては、DEV Communityが的確に整理しています:
"Trust infrastructure for agent commerce requires standardization before widespread deployment—comparable to how SSL had to exist before people would enter card numbers online."(エージェント商取引には信頼インフラの標準化が必要。かつてSSLがなければカード番号を入力できなかったのと同様)
AIエージェント全般の仕組みや現在のエコシステムについては、AIエージェントとは?仕組み・種類・代表ツールまとめも参照してください。
自社でAIエージェント代理を導入するときのチェックリスト
Project Dealは社内実験ですが、企業がAIエージェントを業務に導入する際の示唆は明確です。「自分がHaiku側にならない」ための確認項目を整理します。
観点 | 確認すべきこと |
|---|---|
モデル選定 | 取引・交渉・意思決定を任せる場合、コスト最優先で軽量モデルを選ぶと意思決定品質で損をする可能性。重要度に応じてOpus級/Haiku級を使い分ける |
同等性の担保 | 取引相手のエージェント品質と自分のエージェント品質が極端に乖離していないか。BtoB調達では特に注意 |
監督ループ | 完全自律にするか、閾値(金額・カテゴリ)超過時に人間承認を挟むか。Project Dealは後者を採用しなかった点が設計上の特徴 |
ログ・監査 | 全交渉履歴を保管し、後から検証可能にする |
ハルシネーション対策 | エージェントが架空の根拠で意思決定していないかを抜き取り検証 |
法務・契約 | 自律エージェントが結んだ取引の有効性・責任範囲を契約書面で明確化 |
開示義務 | 取引相手に「AIエージェントが代理で交渉している」ことを開示するか |
プロンプト工学への過信禁止 | 「強気プロンプト」で安いモデルを補おうとしても統計的効果なし。モデル性能自体を選定基準にすること |
特に「自分のエージェントが弱いモデルだと気付けない」という認知盲点は、Project Dealが実証した最も実務的な学びです。導入時にはモデル選定基準を社内で標準化することを推奨します。
マルチエージェント環境の構築方法については、マルチエージェントAIとは?仕組みと活用領域も参考になります。
使用されたClaudeモデル(Opus 4.5 / Haiku 4.5)について
実験で使われた2モデルの公開情報は以下の通りです(実験当時=2025年12月時点)。
モデル | 特徴 | 実験での役割 |
|---|---|---|
Claude Opus 4.5 | 最高性能。複雑な推論・コーディング・エージェント用途に最適 | 実マーケット(Run A)全員使用。比較群としても使用 |
Claude Haiku 4.5 | 高速・低コスト。2025年10月15日リリース。コンテキスト200Kトークン | Opus 4.5との比較用(Run B/C) |
2026年6月現在、後継モデルが登場している可能性があります。最新の料金・性能はAnthropic公式料金ページで確認してください。
Claudeの全体像・使い方はClaudeとは?特徴・料金・使い方を解説、料金体系の詳細はClaude料金プラン徹底解説もあわせて参照してください。
こんな人・企業に参考になる / おすすめしない人
参考にすべき人・企業
- AIエージェントを業務運用に導入したい事業会社 — 自律エージェントの可能性とリスクを一次情報で把握できる
- BtoB調達・社内購買でAIを使いたい担当者 — モデル品質差が交渉結果に直結する具体例として活用できる
- AI倫理・公平性に関心のある研究者・政策担当者 — 「無自覚な格差」という新しい論点を提示している
- 生成AIプロダクトを設計するエンジニア・PdM — エージェント設計時のハルシネーション・人格化問題の参考事例
- AIエージェント経済の将来像を把握したい経営者・投資家 — 技術的可能性と法的課題の両面を俯瞰できる
あまり参考にならない人
- すぐに使える商用サービスを探している人 — Project Dealは研究実験であり、商用プロダクトではない
- 個人の売買やフリマアプリの代替を期待している人 — 一般公開の予定は2026年6月時点で公表されていない
- AIを「単一タスクの自動化ツール」として捉えたい人 — Project Dealの示唆は「エージェント同士の市場」という複雑系設計が前提
よくある質問(FAQ)
Q. Project Dealは商用化される?
公式には商用化や一般公開の予定は明言されていません。Anthropicは研究実験と位置づけており、Project Vend同様、AIエージェント運用の課題を学ぶための社内検証として実施されました。今後の続編や派生プロダクトについては要追跡です。
Q. 一般ユーザーは参加できた?
参加者はAnthropic SFオフィス勤務の従業員69名に限定されており、社外ユーザーは参加していません。Anthropicの管理下で倫理的リスクを抑えるための設計です。
Q. 取引は本当に実際の物品交換が伴った?
Run A(全員Opus 4.5の公開マーケット)のみが実マーケットとして運用され、実際にギフトカードと物品が交換されました。スノーボード・折りたたみ自転車・ラボグロウンルビー・アート作品・犬の日中預かりサービスなど多様なアイテムが実際に受け渡しされています。Run B〜Dは比較研究・コントロール用です。
Q. 「Project Deal」と「Project Vend」の違いは?
Project VendはClaude単体が無人売店を運営する実験で、エージェントが事業者役。Project Dealは多数のClaudeエージェントが市場参加者として相互交渉する実験で、エージェントが代理人役。視点が「事業運営」から「市場参加」へ移った続編です。
Q. 強気プロンプトを与えればHaikuでも十分では?
実験データが明確に否定しています。「徹底的に強気で交渉せよ」という指示を与えても売買確率・価格に統計的有意差は生じませんでした。基礎となるモデルの推論能力がプロンプト工学を上回ることが実証されています。
Q. 結果として一番重要な学びは何?
「弱いモデルに代理されて損をしていても、ユーザーはそれに気づけない」という認知盲点です。公平性スコアがOpus側4.05・Haiku側4.06で有意差がなかった点、さらに39%のユーザーがHaikuの方が「満足だった」と感じた点が、AI代理経済における中心的な倫理課題として位置づけられました。
Q. 自社で似た実験・環境を構築したいときは?
Claude APIでマルチエージェント環境の構築は技術的に可能です。ただし、法務・監査・ハルシネーション対策・開示義務の整備を事前に行うことを推奨します。AIエージェントのフレームワーク比較についてはAIエージェント フレームワーク比較、Claude Managed Agentsの利用についてはClaude Managed Agentsとは?も参照してください。
まとめ:Project Dealが示した「能力非対称性」という新しい論点
Project Dealは、AIエージェント代理経済が技術的に成立しうること、そして能力差が無自覚な経済格差を生むことを同時に示した社内実験です(2025年12月実施・2026年4月公表)。
- 規模:69名・1週間・186件・$4,000超・500点以上出品
- 価格:取引中央値$12、平均$20.05
- 構成:4つの並行Run(A〜D)、Run Aのみ実マーケット
- 発見①:Opus 4.5代理はHaiku 4.5代理より売り手として平均$2.68多く売れ、買い手として$2.45安く買えた
- 発見②:「強気プロンプト」を与えても交渉結果は統計的に変わらない
- 倫理課題:本人は損に気づけない(公平性スコアに有意差なし、39%はHaikuの方が「満足」)
- リスク:品質格差・プロンプトインジェクション・ジェイルブレイク・法的空白・企業の敵対的インセンティブ・ハルシネーション
- 将来展望:MCP標準化(月間97M+ SDKダウンロード)と組み合わさったエージェント経済インフラが整備中
- 位置づけ:研究実験。商用化・一般公開は未定
AIエージェントの導入を検討している方は、「どのモデルを誰の代理にするか」を意思決定の早い段階で標準化しておくことを強く推奨します。Project Dealが提示した「Agent Quality Gap」は、今後の業務AI設計における中心的な論点になっていくはずです。
関連記事
この記事の著者

AI革命
編集部
AI革命株式会社の編集部です。最新のAI技術動向から実践的な導入事例まで、企業のデジタル変革に役立つ情報をお届けしています。豊富な経験と専門知識を活かし、読者の皆様にとって価値のあるコンテンツを制作しています。
最新記事

OpenRouterとは?機能・料金・Claude/GPT/Gemini比較・$1.3B評価額まで解説【2026年5月速報】
2026/06/10

iOS 27 Apple Intelligenceとは?Siri AI・Extensions(Claude/Gemini/ChatGPT/Grok選択)完全ガイド【WWDC 2026正式発表】
2026/05/17

Microsoft 365 Copilotエージェントとは?5種類の機能・Word/Excel/PowerPoint自律実行・料金を徹底解説
2026/06/10

Claude Fable 5とは?料金・性能・Mythos 5との違い・Opus 4.8比較を完全解説【2026年6月速報】
2026/06/10

Sunoとは?料金・機能・V5.5・著作権問題を完全解説【2026年最新】
2026/06/09

Claude 5とは?2026年4月時点の公式ステータス・リリース予測・Opus 4.7との違いを徹底解説
2026/04/18
