NVIDIA Nemotron 3 Nano Omniとは?30B MoEマルチモーダルAIの性能・料金・使い方を徹底解説

この記事のポイント
NVIDIAが2026年4月にリリースした「Nemotron 3 Nano Omni」は、テキスト・画像・動画・音声を1モデルで処理するオープンウェイトAI。最大9倍のスループット・25GB RAM・256Kコンテキストなど、主要スペック・料金・使い方・制約を日本語で徹底解説します。
Nemotron 3 Nano Omniは、NVIDIAが2026年4月28日にリリースした、テキスト・画像・動画・音声の4種類の入力を1つのモデルで処理できるオープンウェイトのマルチモーダル推論AIです。総パラメータ数30B・アクティブパラメータ3BのMixture-of-Experts(MoE)構造により、他のオープンOmniモデルと比べ最大9倍のスループットを実現しています。
この記事では、以下の内容を整理しています。
- 何ができるモデルなのか(4モダリティ対応の具体的な機能)
- 「9倍スループット」とは何を指し、どのような条件で得られるのか
- 料金・利用方法(無料API・有料API・ローカル実行の比較)
- 英語専用モデルという重大な制約と、日本語利用時の現実
- Qwen3-Omniとの使い分け基準
AIエージェント開発者・MLエンジニア・エンタープライズ導入担当者で、マルチモーダルAIの選定や検証を進めている方に向けた技術解説記事です。
Nemotron 3 Nano Omniとは

出典: NVIDIA 公式ブログ
Nemotron 3 Nano Omniは、NVIDIAが開発したオープンウェイトのマルチモーダル推論AIモデルで、正式モデル名は Nemotron-3-Nano-Omni-30B-A3B-Reasoning です。
従来、テキスト処理には言語モデル、画像解析には視覚モデル、音声認識には音声モデルと、用途ごとに別々のモデルを用意する「マルチモデル構成」が一般的でした。Nemotron 3 Nano Omniはこれを1モデルで完結させることを目指した設計で、「Omni」という名称もすべてのモダリティを統合することを意味しています。
項目 | 詳細 |
|---|---|
正式モデル名 | Nemotron-3-Nano-Omni-30B-A3B-Reasoning |
開発元 | NVIDIA |
リリース日 | 2026年4月28日 |
モデルタイプ | マルチモーダル推論AI(Omni) |
総パラメータ数 | 30B |
アクティブパラメータ | 3B(MoE構造) |
アーキテクチャ | Mamba-Transformer ハイブリッド MoE |
ライセンス | NVIDIA Open Model Agreement(商用利用可) |
提供形態 | オープンウェイト(Hugging Face)/API(NIMマイクロサービス) |
入力モダリティ | テキスト・画像・動画・音声 |
出力 | テキストのみ |
「Nano」なのに30B?——MoE構造の仕組み
「Nanoモデルなのに30Bは大きい」と感じた方もいるはずです。これはMoE(Mixture-of-Experts)アーキテクチャの特徴によるものです。
モデルが何かを処理するとき、30Bのパラメータをすべて同時に使うわけではありません。128のエキスパート(専門回路)の中から、そのタスクに最適な上位6つだけを選んで動かすため、実際に計算に使うパラメータは約3B相当になります。「豊富な専門家集団の中から、最適なメンバーだけを呼び出す」イメージです。
この設計により、同等の性能を持つ全密度(Dense)モデルと比べて、メモリ消費と計算コストを大幅に抑えられます。
できること——4モダリティ統合処理の具体的な機能
Nemotron 3 Nano Omniは、単に「複数の入力を受け付ける」だけでなく、用途ごとに実用的な精度を持つ機能を複数備えています。
対応する入力・出力の仕様
入力モダリティ | 対応フォーマット | 制限 |
|---|---|---|
テキスト | 文字列 | 英語のみ(現時点での公式対応) |
画像 | JPEG・PNG(RGB) | 最大1,840×1,840相当(13,312パッチ) |
動画 | MP4 | 最大2分/1〜2FPS/128〜256フレーム推奨 |
音声 | WAV・MP3(8kHz以上) | 最大1時間(推論時) |
非対応 | PNG/JPEGに変換してから使用 | |
出力 | テキストのみ | 画像・音声・動画の生成は不可 |
主要機能と精度の実態
1. 長文書理解・OCR
業界標準ベンチマーク「MMLongBench-Doc」で1位(57.5点)、「OCRBenchV2-En」でも1位(65.8点)。大量のドキュメントを処理する業務に強みがあります。
2. グラフ・チャート解析
CharXiv Reasoningスコアは63.6点で、前世代モデル比+35%の改善。財務レポートや科学論文のグラフ解析に活用できます。
3. コンピュータ使用(GUIエージェント)
OSWorldスコア47.4(前世代の11.0から大幅改善)。1,920×1,080解像度のデスクトップ画面を見て操作を推論する、エージェントワークフローへの組み込みが可能です。
4. 動画+音声の統合理解
動画と音声を同時に処理し、複合的な質問に答えます。DailyOmniベンチマークで74.1点、WorldSenseで55.4点。
5. 自動音声認識(ASR)
VoiceBenchで89.4点・HuggingFace Open ASR LeaderboardのWER(単語誤り率)5.95%は業界最低水準クラスです。英語音声の文字起こし精度は非常に高いといえます。
6. 推論(チェーンオブソート)
最大16,384トークンの推論バジェットで複雑な問題を段階的に解きます。
7. ツール呼び出し(Tool Calling)
外部ツール・APIを呼び出す形式の関数実行に対応しており、AIエージェントとしての組み込みに活用できます。
8. 超長コンテキスト
最大256Kトークン(実験的には300K)に対応。大量の文書をまとめて処理する用途に適しています。
アーキテクチャの仕組み——Mamba×MoE×マルチモーダルの設計
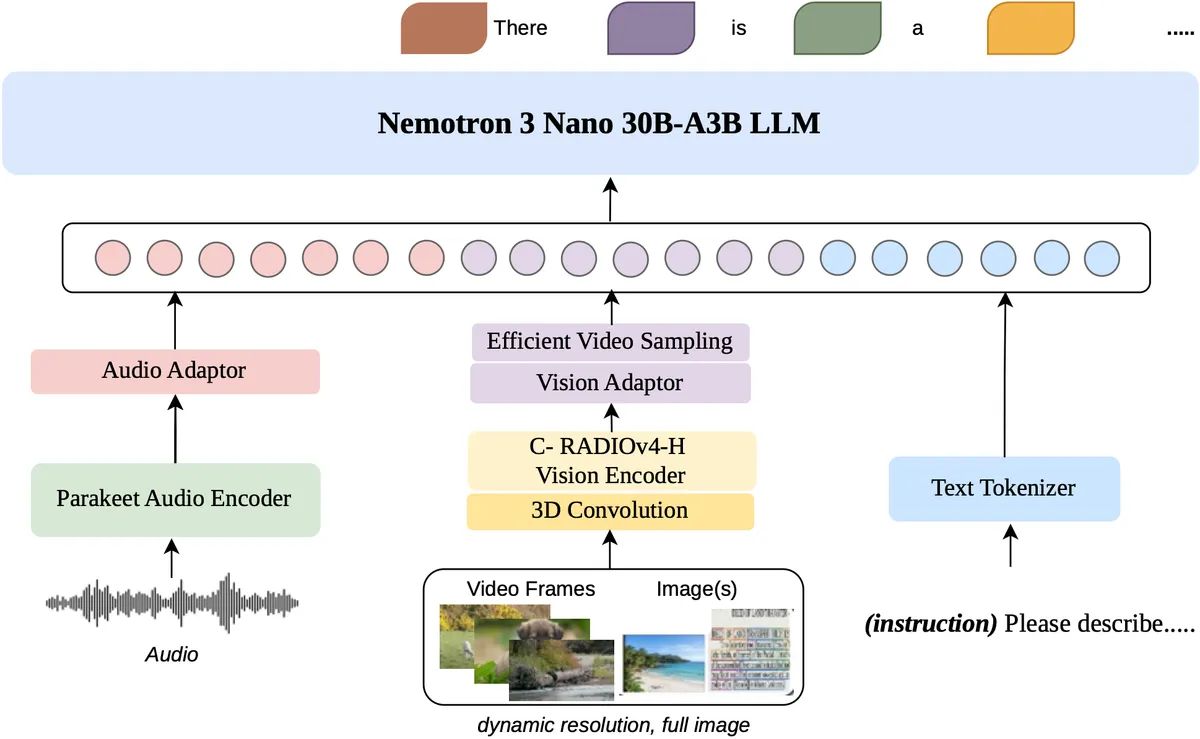
Nemotron 3 Nano Omniは、次の3つのコンポーネントで構成されています。
言語バックボーン:Nemotron 3 Nano 30B-A3B
モデルの中核となる言語処理部です。3種類の層を組み合わせたハイブリッド構造になっています。
- 23層 Mamba(選択的状態空間モデル): 長文テキストの効率的な記憶・処理を担当。Transformerの注意機構が苦手とする「長い文脈の圧縮処理」を効率的に行います。
- 23層 MoE層(128エキスパート・top-6ルーティング/共有エキスパート付き): タスクに応じた専門回路を選択して処理。全パラメータを常時使用しないため計算コストを低減します。
- 6層 グループ化クエリアテンション: 細部の精密な推論が必要な場面でTransformer型の注意機構を使用します。
この構成のポイントは役割分担です。Mambaが「長文を効率的に記憶する係」、アテンション層が「細部を精密に推論する係」として機能し、MoEが「どのエキスパートを使うかを振り分ける係」として全体を統括します。
視覚エンコーダ:C-RADIOv4-H
512×512から1,840×1,840まで動的に解像度を変化させながら画像を処理します。処理後は2層のMLPプロジェクタで言語空間に変換します。
動画処理には2つの革新技術を採用しています。
- Conv3D(3D畳み込み): 連続フレームをTubelet埋め込みに変換し、視覚トークン数を50%削減。同じトークン数でも2倍のフレームを処理できます。
- EVS(効率的動画サンプリング): 動き検出で変化のある部分のみを保持し、静的フレームを削除。レイテンシを下げながら精度を維持します。
音声エンコーダ:Parakeet-TDT-0.6B-v2
16kHzサンプリングレートで音声を処理し、2層のMLPプロジェクタで言語空間に投影します。
「9倍スループット」の実態——条件と数値を正確に把握する
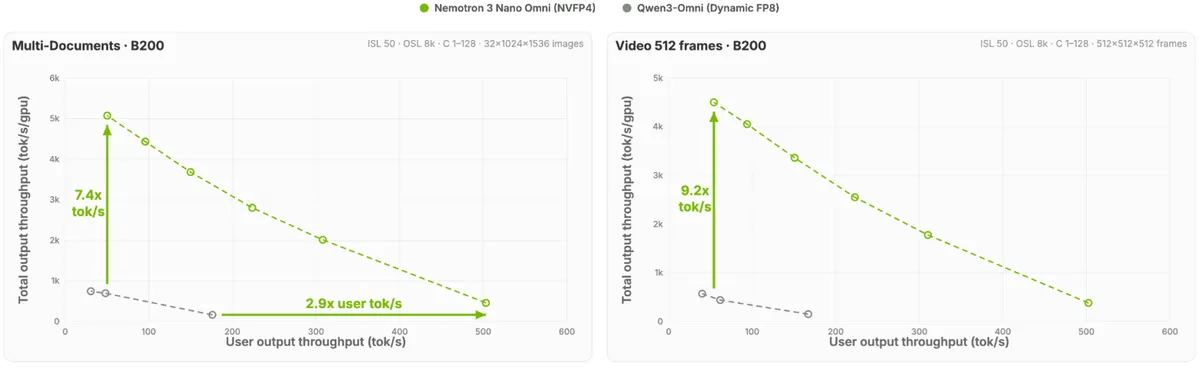
「最大9倍のスループット」という数値が独り歩きしがちですが、この数値には具体的な比較条件があります。
スループット数値の条件
指標 | 数値 | 比較対象・条件 |
|---|---|---|
動画推論スループット | 約9.2倍 | Qwen3-Omni比、B200 GPU上 |
マルチドキュメント推論 | 約7.4倍 | Qwen3-Omni比、B200 GPU上 |
全体最大スループット | 最大9倍 | 他オープンOmniモデル比(NVFP4使用時) |
単一ストリーム推論速度 | 2.9倍 | 同上 |
メモリ・計算効率 | 4倍 | 同規模Transformerモデル比 |
TTFT(マルチドキュメント) | 約1.3秒 | Qwen3-Omniの2.5秒超と比較、B200使用 |
独立評価機関による実測(Coactive MediaPerf)
独立評価機関Coactive AIのMediaPerfベンチマークでは以下の結果が確認されています。
- 動画タギングスループット: Nemotron 9.91 h/h vs Qwen3-VL 約3.8 h/h
- GPT-5.1が処理完了まで18.37時間を要したタスクを、Nemotronは8.30時間で完了(2倍以上高速)
DGX Spark実測値(Classmethod調査、2026年5月)
DGX Spark(GB10 GPU/128GB統合メモリ、CUDA 13.0、vLLM 0.20.0)上での実測ベンチマーク:
バリアント | レイテンシ | スループット |
|---|---|---|
NVFP4(約21GB) | 6.63秒 | 56.94トークン/秒 |
FP8(約33GB) | 7.88秒 | 50.70トークン/秒 |
モダリティ別のレスポンス時間(NVFP4):
モダリティ | 処理時間 | 生成トークン数 |
|---|---|---|
テキスト | 4.87秒 | 277トークン |
画像(PPE検出) | 2.04秒 | 108トークン |
音声(英語16秒) | 0.85秒 | 43トークン |
動画(コンベア15秒) | 0.64秒 | 15トークン |
同条件でのGemma 4 31B IT比較(PPE画像タスク)では、Nemotronが0.67秒・Gemma 4 31Bが9.78秒という結果で、約14.6倍の速度差が確認されています。
「9倍」を読む際の注意点: この数値はB200 GPUという最新・高性能なハードウェア上での計測値です。一般的なGPU環境では差は縮まる可能性があります。また、NVFP4(4-bit量子化)使用時の数値である点にも注意が必要です。
料金・利用方法——無料APIからセルフホストまでの選択肢
Nemotron 3 Nano Omniには大きく3つの利用方法があり、それぞれコスト・柔軟性・プライバシー面の特性が異なります。
1. 無料APIで試す(OpenRouter)
現時点(2026年5月)では、OpenRouterで完全無料のフリー枠が提供されています。
項目 | 内容 |
|---|---|
モデルID |
|
入力料金 | $0 / Mトークン |
出力料金 | $0 / Mトークン |
レート制限 | 非公開(変動あり) |
利用開始 | OpenRouterアカウント登録のみ |
無料枠の条件はOpenRouter側の判断で変更される場合があります。長期・大量利用の場合は有料プランへの移行を前提に計画してください。
2. 有料APIを使う(複数プラットフォーム)
プラットフォーム | 特徴 |
|---|---|
Baseten | API推論専用インフラ |
DeepInfra | 低コスト推論API |
Fireworks AI | 高速推論特化 |
Together AI | 幅広いモデル対応 |
Crusoe | エネルギー効率特化 |
AWS SageMaker JumpStart | AWSエコシステム内で完結 |
有料APIの料金相場(参考)は入力$0.050/Mトークン〜、出力$0.200/Mトークン〜程度です。NVIDIA NIM(build.nvidia.com)の最新料金は公式サイトを直接確認してください。
3. ローカル実行・セルフホスト
機密情報を含む映像・音声・文書を処理する場合や、外部APIへの依存を避けたい場合は、ローカル実行が選択肢になります。
精度バリアント | モデルサイズ | 最低VRAM/RAM目安 |
|---|---|---|
NVFP4(4-bit相当) | 約20.9 GB | 約25 GB |
FP8 | 約32.8 GB | 約36 GB |
BF16(フルプレシジョン) | 約61.5 GB | 60 GB以上 |
「25GB RAM」というキーワードが注目される理由は、Unslothの公式ドキュメントに「4-bit量子化バージョン(UD-Q4-K-XL)は約25GB RAM/VRAMが必要」と明記されているためです。マルチモーダルエンコーダ・KVキャッシュを含めた実運用メモリとして25GBが目安になります。
対応ハードウェア・インフラ:
カテゴリ | 対応環境 |
|---|---|
エッジ/ローカル | NVIDIA DGX Spark、DGX Station、Jetson Thor、RTX 5090 |
推論エンジン | vLLM(v0.20.0+)、TensorRT-LLM、SGLang、llama.cpp、LM Studio、Unsloth |
クラウドGPU | AWS SageMaker JumpStart、Oracle Cloud(予定)、Azure(予定) |
開発ツール | Hugging Face、NVIDIA NeMo、Megatron-LM |
⚠️ セルフホスト時の重要注意点:CUDA 13.2バグ
現時点(2026年5月)で、CUDA 13.2を使用すると出力が文字化けするバグが確認されています。CUDA 13.0を使用してください。 NVIDIAが修正中ですが、完了時期は未公表です。CUDAバージョンの確認をセットアップの最初のステップとして実施することを強くおすすめします。
用途別おすすめ利用構成
用途 | 推奨構成 | 備考 |
|---|---|---|
まず動作確認・評価 | OpenRouter 無料枠 |
|
英語文書の大量バッチ処理 | Baseten / Fireworks AI 有料API | スループット最大化 |
機密文書・社内映像の処理 | DGX Spark / RTX 5090 セルフホスト(NVFP4) | 約25GB VRAMが目安 |
AWSエコシステム内での運用 | SageMaker JumpStart | AWS Marketplace経由 |
エッジ環境でのリアルタイム処理 | Jetson Thor | NVIDIA公式サポート |
最高精度が必要な推論 | BF16フルプレシジョン(セルフホスト) | 60GB+ VRAM必要 |
できないこと・注意すべき制約

出典: NVIDIA 技術ブログ
Nemotron 3 Nano Omniを業務や開発に組み込む前に、以下の制約は必ず把握しておく必要があります。
制約事項 | 詳細 |
|---|---|
英語のみ対応 | テキスト入力は英語のみ公式サポート。日本語質問には英語で回答するケースが多い |
日本語精度の低さ | JCommonsenseQA v1.1で88.03%(Gemma 4 31Bの97.77%より約10pt低い) |
PDF直接入力不可 | PDFはPNG/JPEGに変換してから使用する必要あり |
動画の上限2分 | 超過分は処理不可 |
出力はテキストのみ | 画像・動画・音声の生成はできない |
Ollamaでマルチモーダル不可 | 現時点でテキストモードのみ( |
CUDA 13.2バグ | 使用すると出力が文字化け。CUDA 13.0を使用すること |
推論がデフォルトオン | 単純タスクでも推論モードが動作し、レイテンシが増加する場合あり |
学習データに競合モデル出力を使用 | 商用利用時はライセンスチェーンの確認が必要 |
日本語対応の現実
Classmethodの実測によると、日本語テキストを入力すると英語で回答することが多く、実質的に英語専用モデルとして扱う必要があります。日本語の画像テキスト(警告サインのOCRなど)については部分的に対応が確認されています。
現時点で日本語業務への導入を検討している場合、Qwen3-VLやGemma 4 31B-ITなど多言語対応モデルとの併用または代替が現実的です。
ライセンスと学習データの透明性
Nemotron 3 Nano OmniはNVIDIA Open Model Agreement(商用利用可)ですが、Apache 2.0よりやや制限が多い点に注意が必要です。また、NVIDIAは学習データに競合モデル(Qwen3-VL、GPT-OSS、DeepSeek-OCR等)の出力を合成データ生成に使用していることを公式に開示しています。
透明性という観点では業界標準を上回る開示と評価されていますが、商用利用を検討する場合はライセンスチェーンの法的リスクを自社の法務担当者に確認することを推奨します。
Qwen3-Omniとの比較
マルチモーダルOmniモデルの主要な比較対象はQwen3-Omniです。両者を中立的に整理します。
比較項目 | Nemotron 3 Nano Omni | Qwen3-Omni |
|---|---|---|
動画推論スループット | 約9.2倍高い | 基準(1倍) |
マルチドキュメントスループット | 約7.4倍高い | 基準(1倍) |
ライセンス | NVIDIA Open Model Agreement | Apache 2.0(制限少ない) |
日本語対応 | 限定的(英語専用) | 多言語対応(日本語含む) |
ベンチマーク精度 | ほぼ同等 | ほぼ同等 |
アーキテクチャ | Mamba-Transformer MoE | Transformer MoE |
コンテキスト長 | 最大256K(実験的300K) | 最大128K |
OCR・文書理解 | MMLongBench-Doc 1位 | 上位 |
ASR精度(英語) | WER 5.95%(業界最低水準) | 高い |
商用ライセンス自由度 | やや制約あり | 自由度高い |
スループット・英語文書処理量を最大化したいならNemotron、ライセンスの自由度や日本語を含む多言語対応が必要ならQwen3-Omniというのが現時点の使い分け基準です。精度の優劣は両者でほぼ同等(ノイズ範囲内)とされており、選択の主要因はスループット要件とライセンス要件になります。
NVIDIAのNemotronシリーズでの位置づけ
Nemotron 3 Nano Omniは、NVIDIAのNemotronファミリーの一部です。他のシリーズモデルとの関係を把握しておくと、用途別の選択がしやすくなります。
モデル名 | 規模 | 特化用途 | 特徴 |
|---|---|---|---|
Nemotron 3 Nano Omni(本記事) | 31B / アクティブ3B | マルチモーダルエージェント | テキスト・画像・動画・音声を1モデルで処理 |
Nemotron Nano V2 VL | — | 視覚言語(テキスト+画像) | 音声・動画は非対応 |
Nemotron Super 120B | 120B | 高精度テキスト推論 | 大規模クラウド向け |
Nemotron-H 8B / 56B | 8B・56B | テキスト推論・コーディング | Mamba2ハイブリッドアーキテクチャ |
マルチモーダル(4モダリティ入力)が必要な場合はNemotron 3 Nano Omni、テキスト推論・コーディング特化が必要な場合はNemotron-Hシリーズ、テキスト+画像のみのシンプルな視覚言語タスクにはNemotron Nano V2 VLが適しています。
こんな人におすすめ / おすすめしない人
こんな人・用途におすすめ
- 大量の英語ドキュメントを高速処理したい(財務レポート・論文・契約書など)
- 動画+音声の統合解析システムを構築したい(監視カメラ解析・メディア処理パイプライン等)
- AIエージェントにGUI操作(コンピュータ使用)を組み込みたい
- スループットが最優先で、日本語は英語翻訳経由で対応できる
- オープンウェイトモデルのセルフホストで機密情報を社内に留めたい
- OpenRouterの無料枠でまず評価・検証したい
- B200 GPUやDGX Sparkなど、NVIDIAの最新ハードウェアを所有している
- Foxconn・Palantirなど大規模製造・データ企業向けパイプラインを構築したい
おすすめしない人・向かない用途
- 日本語での自然な対話や日本語文書処理が主目的の場合(英語専用モデルのため)
- PDFを直接処理したい(PNG変換ステップが必要)
- Ollamaでマルチモーダルを実行したい(現時点でテキストのみ)
- Apache 2.0相当のライセンスで完全自由な商用利用が必要(NVIDIA Open Model Agreementの制約あり)
- CUDA 13.2環境を変更できない場合
- 出力として画像・音声・動画を生成したい(テキスト出力のみ)
- 2分以上の長尺動画をシームレスに処理したい(2分上限あり)
- 汎用チャットボットや日常的な会話AIを構築したい(専門的な推論モデルのため、単純タスクでも推論モードが動作しレイテンシが増加)
よくある質問(FAQ)
Q. 日本語でも使えますか?
現時点での公式対応言語は英語のみです。Classmethodの実測でも、日本語テキストを入力すると英語で回答するケースが多く確認されています。日本語精度はJCommonsenseQA v1.1で88.03%(Gemma 4 31Bの97.77%より低い)。日本語業務への本格利用は現時点では推奨できません。
Q. ChatGPTやClaudeと何が違いますか?
ChatGPT(GPT-4o)やClaudeは主にクラウドAPIのみの提供で、モデルのウェイトは非公開の商用クローズドモデルです。Nemotron 3 Nano Omniはオープンウェイトでセルフホスト可能なため、独自インフラでの運用や機密データ処理に適しています。ただし、日本語対応や汎用会話品質の面ではChatGPT・Claudeが優れています。
Q. Ollamaで動かせますか?
現時点(2026年5月)では、OllamaはNemotron 3 Nano Omniのテキストモードのみ対応しており、マルチモーダル機能(画像・音声・動画)は利用できません。mmprojファイルの分離問題が原因で、対応時期は未公表です。
Q. 25GBのVRAMが必要ですか?
最低構成(NVFP4・4-bit量子化)での目安が約25GBです。FP8では約36GB、BF16フルプレシジョンでは60GB以上が必要です。マルチモーダル処理時はエンコーダやKVキャッシュの分が加算されるため、テキスト専用の試算より多く見積もってください。
Q. PDFを直接入力できますか?
直接は対応していません。PDFの各ページをPNG/JPEG画像に変換してから画像として入力する必要があります。Pythonのpdf2imageライブラリなどで変換してから使用してください。
Q. ライセンスは商用利用可能ですか?
NVIDIA Open Model Agreementのもとで商用利用は可能です。ただしApache 2.0より制約が多く、学習データに競合モデルの出力が含まれている点についても、商用利用前に自社の法務確認を推奨します。
Q. 前世代「Nemotron Nano VL V2」とは別物ですか?
別モデルです。「Nemotron 3 Nano Omni」(本記事)はテキスト・画像・動画・音声の4モダリティを扱うOmniモデルです。「Nemotron Nano V2 VL」は視覚言語モデル(テキスト+画像のみ)で音声・動画には非対応です。また、テキスト専用のNemotron-3-Nano-30B-A3B(Omniなし)とも異なります。
Q. 「推論がデフォルトオン」とはどういう意味ですか?
このモデルはReasoningという名称の通り、デフォルトで推論(チェーンオブソート)が動作します。「今日の天気は?」のような単純な質問でも推論プロセスが走り、応答までの時間が長くなる場合があります。レイテンシを重視する場合はプロンプト設計で制御するか、用途によっては推論モードをオフにする方法(モデル設定による)を検討してください。
まとめ
NVIDIA Nemotron 3 Nano Omniは、2026年4月28日にリリースされたオープンウェイトのマルチモーダル推論AIです。30Bパラメータ・3BアクティブのMoE構造により、Qwen3-Omniと比べ動画処理で最大9.2倍、マルチドキュメント処理で7.4倍という構造的スループット優位性を持ちます。
このモデルの最大の強みは、スループットとオープンウェイトの組み合わせです。大量の英語ドキュメント・動画を高速処理するパイプラインや、社内インフラでのセルフホスト運用、AIエージェントへの組み込みに向いています。
一方で、英語専用モデルであることが現時点での最大の弱点です。日本語業務への本格導入には、他の多言語対応モデルとの組み合わせが必要になります。また、CUDA 13.2バグやOllamaでのマルチモーダル非対応など、セルフホスト時に踏むべき地雷も複数あります。
OpenRouterの無料枠で今日から試せるので、まず評価用の小規模テストから始めることをおすすめします。
関連記事:
この記事の著者

AI革命
編集部
AI革命株式会社の編集部です。最新のAI技術動向から実践的な導入事例まで、企業のデジタル変革に役立つ情報をお届けしています。豊富な経験と専門知識を活かし、読者の皆様にとって価値のあるコンテンツを制作しています。
最新記事

ChatGPT for Academic Researchersとは?12カ月無償・応募条件・日本の対象大学・GPT-5.6 Sol Pro特典を解説
2026/07/31

製薬メーカー・製薬業のAI活用事例|創薬・治験・品質管理を徹底解説【2026年版】
2026/04/21

Google Lyria 3.5とは?Flow Musicの最新音楽生成AI|最大3分・日本語ボーカル・Lyria 3 Proとの違い・料金と使い方【2026年7月最新】
2026/07/31

ガバメントAI「源内」とは?デジタル庁OSS公開・18万人展開・熊本地震での緊急提供まで【2026年7月最新】
2026/04/28

Claude大規模障害まとめ|2026年7月29-30日のダウンと529 Overloadedエラーの意味・対処法
2026/07/31

Claude Fable 5とは?料金・性能・Mythos 5との違いとOpus 5との使い分け【2026年7月最新】
2026/06/10
