Claude Opus 4.7とは|SWE-bench Pro 64.3%・GPT-5.4超えの性能と料金徹底解説

この記事のポイント
Claude Opus 4.7はAnthropicが2026年4月16日に公開した一般提供モデル最高性能のClaude Opus系モデル。SWE-bench Pro 64.3%でGPT-5.4を上回りながら料金は4.6から据え置き。新トークナイザーによる実効コスト増・Mythos Previewとの違い・GPT-5.4/Gemini 3.1 Proとの比較まで整理します。
Claude Opus 4.7は、Anthropicが2026年4月16日に一般提供開始した、Claude Opus系で最も高性能なフラッグシップモデルです。ソフトウェアエンジニアリング向けベンチマーク「SWE-bench Pro」で64.3%を記録し、GPT-5.4(57.7%)やGemini 3.1 Pro(54.2%)を引き離しました。料金は前世代のOpus 4.6から据え置きで、入力$5/出力$25(100万トークンあたり)です。
この記事でわかること:
- Claude Opus 4.7の基本情報と、Opus 4.6から何が変わったのか
- 「GPT-5.4超え」がどのベンチマークで成立し、どこでは横並び・劣るのか
- 料金が据え置きでも実効コストが上がりうる「新トークナイザー」の注意点
- 一般非公開の上位モデル「Claude Mythos Preview」との関係と使い分け
- Pro / Max / Team / API / Amazon Bedrock / Vertex AI などアクセス経路の整理
この記事が向いている人: 最新のClaudeフラッグシップモデルを業務に導入すべきか判断したい開発者・情報システム担当者・AI活用を推進する事業責任者。

出典: Anthropic 公式サイト
Claude Opus 4.7とは(基本情報)
Claude Opus 4.7は、Anthropicが提供する大規模言語モデル「Claude」シリーズの最上位クラス「Opus」系の現行世代です。2026年4月16日に一般提供(GA)として公開され、Web・モバイルアプリ(claude.ai)、Claude API、Amazon Bedrock、Google Cloud Vertex AI、Microsoft Foundry、GitHub Copilot、Snowflake Cortex AIの各プラットフォームで同日から利用できます。
前世代のOpus 4.6からのマイナーバージョンアップという位置づけで、コーディング・長時間エージェント運用・指示追従・ビジョン(画像入力)の4領域が中心に強化されました。APIモデルIDは claude-opus-4-7(Anthropic直接API)、us.anthropic.claude-opus-4-7(Amazon Bedrock)です。
前提として押さえておきたい3点
Opus 4.7を正しく理解するには、次の3点を先に知っておくと混乱が減ります。
- 「一般提供モデル」として最強を狙うモデルである — Anthropicは内部に Opus 4.7 より高性能な「Claude Mythos Preview」を持っているが、整合性(alignment)とサイバー誤用懸念から一般提供していない。Opus 4.7は「安全に一般公開できる範囲で最高性能」というポジション。
- 料金は Opus 4.6 と完全据え置き(入力$5/出力$25)だが、新しいトークナイザーによって同じ日本語・同じコードでもトークン数が最大+35%増える可能性がある。
- 「GPT-5.4超え」はコーディング系ベンチマークでの事実であり、すべての領域で優位というわけではない。GPQA Diamond(大学院レベルの推論)では3モデル横並び、動画理解(Video-MME)ではGemini 3.1 Proが優位。
Opus 4.6からの進化点
Opus 4.7は、Opus 4.6で課題として残っていた「難問でのコーディング成功率」「長時間タスクの安定性」「画像の読解精度」を中心に底上げされています。Anthropic公式は Opus 4.6比で以下の改善幅を示しています。
項目 | 改善幅 | 備考 |
|---|---|---|
コーディングタスク解決率 | +13% | Opus 4.5・4.6で解けなかった問題も解ける水準に |
エージェント運用時のツール呼び出しエラー | 約1/3に減少 | 長時間の自律実行における安定性向上 |
ビジョン入力の最大解像度 | 長辺1,568 → 2,576px(約3倍の視覚情報量) | 複雑な技術図面・UIキャプチャの読解精度向上 |
CyberGym(サイバー防御系ベンチ) | 66.6 → 73.8 | 防御用途の能力は強化 |
出典: Introducing Claude Opus 4.7 — Anthropic、AWS Blog
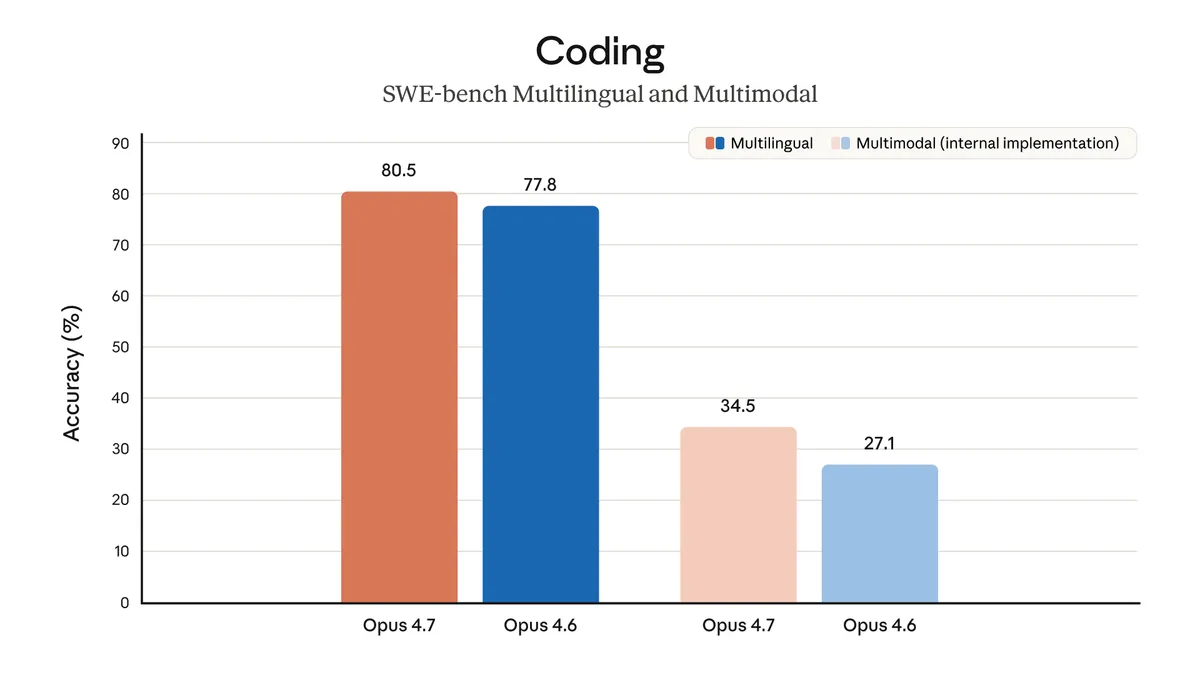
ソフトウェアエンジニアリング
最難関クラスの問題でのブレイクスルーが中心で、Opus 4.6では解けなかった種類の問題も解けるケースが報告されています。Claude Code環境向けには/ultrareviewコマンド(深掘りコードレビュー専用モード)が追加され、複雑なPR・大型差分でも一貫性のあるレビューが返せるように設計されました。
長時間エージェント運用
数時間単位で自律的にタスクを回す用途(多段階のリサーチ、大量ファイル編集、複数ツール連携など)での安定性が大きく改善しています。ツール呼び出しエラーが約3分の1に減ったことで、人間の巻き戻し・再実行コストが下がる見込みです。
指示追従(instruction following)
指示の読み取り精度が上がっている一方で、Opus 4.6時代に「ふんわり効いていた」プロンプトが通らなくなるケースがあります。既存プロンプトを流用する場合は、テスト→調整を前提にすると安全です。
ビジョン
入力画像の最大サイズが「長辺1,568ピクセル」から「長辺2,576ピクセル(約3.75メガピクセル)」に拡大されました。視覚情報量で約3倍になるため、技術図面・化学構造式・密なテキストが載ったPDF・画面UIキャプチャなど「細部まで読ませたい画像」の用途で効いてきます。
出典: Anthropic 公式サイト
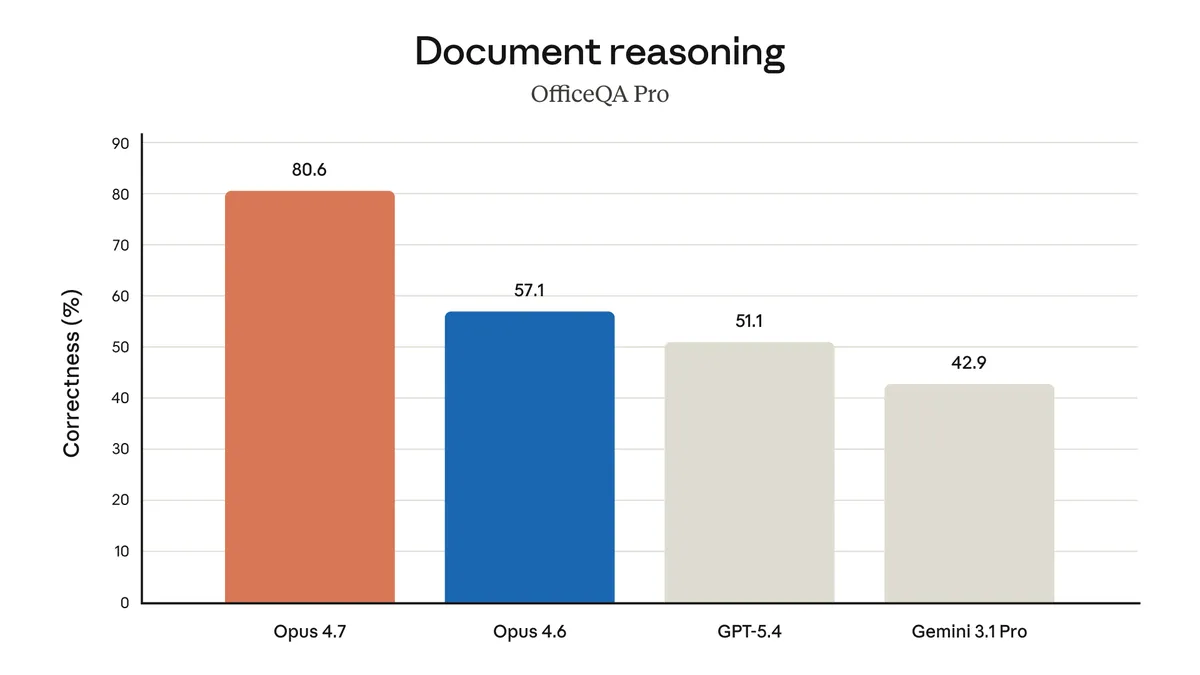
「GPT-5.4超え」の実態:どこで勝ち、どこでは並ぶか
Opus 4.7の「GPT-5.4超え」という訴求は事実ですが、対象領域はコーディング・エージェント系に限定されます。すべてのベンチマークで一律に勝っているわけではない点を踏まえ、以下の表で整理します。
出典: Anthropic 公式サイト
ベンチマーク | Opus 4.7 | Opus 4.6 | GPT-5.4 | Gemini 3.1 Pro | Opus 4.7の位置 |
|---|---|---|---|---|---|
SWE-bench Pro(実世界コーディング) | 64.3% | — | 57.7% | 54.2% | トップ |
SWE-bench Verified | 87.6% | 80.8% | — | 80.6% | トップ |
Terminal-Bench 2.0 | 69.4% | — | — | — | — |
Finance Agent v1.1 | 64.4% | — | — | — | — |
CursorBench(Cursor内性能) | 70% | 58% | — | — | — |
GPQA Diamond(大学院レベル推論) | 94.2% | — | 94.4%(Pro) | 94.3% | ほぼ横並び |
CyberGym(サイバー防御) | 73.8 | 66.6 | — | — | — |
Video-MME(動画理解) | 71.4%(参考) | — | — | 78.2% | Geminiが優位 |
出典: VentureBeat、TheNextWeb、AWS Blog
読み取りの要点
- コーディング系は明確にトップ — SWE-bench ProでGPT-5.4を+6.6pt、Gemini 3.1 Proを+10.1pt引き離している。SWE-bench Verifiedでも87.6%で同世代最高。「コーディングを任せる主力モデル」として選ぶなら現時点の最有力候補。
- 汎用推論は横並び — GPQA Diamondは94.2〜94.4%で3モデル実質同等。「理系の大学院レベルの問題を解く」用途ではモデル選択よりプロンプト設計の方が効く。
- 動画理解はGeminiが依然優位 — Video-MMEのような動画コンテンツ理解が主戦場の場合、Gemini 3.1 Proの方が素直に強い。
執筆品質(ブラインド人間評価)
VentureBeatが参照しているブラインド評価では、Opus 4.6世代の段階で「Claude 47% / GPT-5.4 29% / Gemini 3.1 Pro 24%」という結果が出ており、Opus 4.7ではさらに改善している見込みです。ビジネス文書・提案書・長文ナラティブの執筆では、ベンチマーク数値以上の差を体感できる可能性があります。
Claude Opus 4.7の料金(API・Pro・Max・Team)
料金はOpus 4.6から据え置きです。ただし後述するとおり、新しいトークナイザーの影響で同じテキストでも実効コストが1.0〜1.35倍のレンジで変動します。API従量課金は以下のとおり。
API従量課金(100万トークンあたり・USD)
項目 | 単価 |
|---|---|
入力(Base) | $5 |
5分プロンプトキャッシュ(書き込み) | $6.25 |
1時間プロンプトキャッシュ(書き込み) | $10 |
プロンプトキャッシュ(読み込み・ヒット) | $0.50 |
出力 | $25 |
割引オプション:
- プロンプトキャッシュ活用で入力コストを最大90%削減
- Batch API経由で50%割引(実質入力$2.50/出力$12.50)
- 1Mトークンのロングコンテキストは追加プレミアムなし(Opus 4.7 / 4.6 / Sonnet 4.6 / Mythos Preview共通)
- データレジデンシ用途で
inference_geo: "us"を指定した場合は1.1倍の乗算
出典: Claude API Pricing — 公式ドキュメント
消費者向けプラン(claude.ai)
Opus 4.7は以下のプランで利用できます。具体的なメッセージ上限・トークン上限は公式ドキュメントで明示されていないため、必ず最新のプラン表で確認してください。
- Claude Pro
- Claude Max
- Claude Team
- Claude Enterprise
プラン別の料金・上限の詳細は Claude料金 および Claude Max プラン解説 を参照してください。
⚠️ 新トークナイザーによる実効コスト増(最重要の注意点)
Anthropic公式ドキュメントは次のように明記しています。
Opus 4.7 uses a new tokenizer compared to previous models, contributing to its improved performance on a wide range of tasks. This new tokenizer may use up to 35% more tokens for the same fixed text.
つまり、同じ日本語文章・同じソースコードでも、Opus 4.6時代と比べて最大+35%のトークンを消費する可能性があるということです。単価は据え置きでも、実効コストは次のレンジで見積もるのが安全です。
- 実効コスト倍率:1.0〜1.35倍(テキスト種別による)
- 見積もり例:Opus 4.6で月$1,000の従量課金だった場合、同じ用途でOpus 4.7は$1,000〜$1,350を想定
コストセンシティブな大量処理(バックグラウンドの要約・分類など)では、Opus 4.7に切り替える前に小規模トラフィックで実効コストを必ず計測することを推奨します。
新機能まとめ(xhigh / Task Budgets / Cyber Verification Program)
Opus 4.7のリリースと同時に、次の機能・プログラムが追加されました。
機能 | 概要 | ステータス |
|---|---|---|
| 推論の深さとレイテンシを従来より細かく制御できる新しいeffortレベル | GA |
Task Budgets | タスク単位で推論予算(トークン数)を制御する仕組み | Public beta |
強化されたファイルシステム・メモリ | 複数セッションをまたいだ作業記憶の継続 | GA |
| Claude Code向けのコードレビュー深掘りモード | GA |
Cyber Verification Program | セキュリティ研究者向けに、検証済みアカウントでガードレールを一部緩和する新プログラム | 申請制 |
Cyber Verification Program
Opus 4.7は訓練段階でサイバー関連の攻撃的能力を意図的に削減しており、プロンプト注入やサイバー攻撃用途の自動ブロック機構を搭載しています。一方で、脆弱性リサーチ・ペネトレーションテスト・レッドチーミングといった正当なセキュリティ業務向けには、申請制のCyber Verification Programが用意されており、検証済みアカウントでは拡張アクセスが得られます。
出典: Introducing Claude Opus 4.7 — Anthropic
Claude Opus 4.7の強み
実務観点でOpus 4.7の強みをまとめると以下になります。
- 一般提供モデルで最強クラスのコーディング性能 — SWE-bench Pro 64.3%は2026年4月時点で公開モデル中トップ。複雑なバグ修正・大型リファクタ・レビュー自動化など「難易度の高いコーディングタスク」に強い。
- 長時間の自律エージェント運用に耐える — ツール呼び出しエラーが約1/3に減り、数時間規模のタスクでも途中で崩れにくい。
- ビジョン精度の向上 — 長辺2,576pxまで取り込めるため、細かいUIキャプチャ・設計図・論文図表の読解に強い。
- 執筆品質が継続的にトップ水準 — Opus系伝統の「自然な日本語・骨太な構成」は健在。長文ドキュメント生成で差がつきやすい。
- 1Mトークンのロングコンテキストを追加料金なしで扱える — 大規模コードベース・長編ドキュメントを一括で読み込ませる用途に有利。
- アクセス経路が広い — Claude API・Amazon Bedrock・Google Cloud Vertex AI・Microsoft Foundry・GitHub Copilot・Snowflake Cortex AIと主要クラウドをほぼ網羅。既存のクラウド契約・セキュリティ承認フローに組み込みやすい。
Claude Opus 4.7の弱み・注意点
逆に、Opus 4.7を選ぶ前に理解しておきたい弱点・制約です。
- 新トークナイザーで実効コストが最大+35% — 単価据え置きに惑わされず、実トラフィックで必ず計測する。
- 「最高性能」ではない — Anthropic内部のClaude Mythos Previewの方がコーディング・整合性ともに上。Opus 4.7は「安全に一般公開できる範囲での最高性能」。
- プロンプトの再調整が必要な場合がある — 指示追従が精密化した影響で、Opus 4.6で動いていたプロンプトが意図どおりに動かないケースがある。本番切替前にリグレッションテスト必須。
- サイバー攻撃系の能力は意図的に抑制 — 正当なセキュリティ研究でも、Cyber Verification Programの申請を通さないと一部の挙動は制限される。
- 動画理解はGemini 3.1 Proに劣る — 動画コンテンツ解析が主用途ならGemini系の検討も必要。
- 合成有害物質のハーム・リダクション助言に弱点 — Anthropic公式リリースノートで「modest weaknesses」として明記されている。
- Pro / Max / Team のOpus 4.7利用上限は公式に明示されていない — 現時点の公式ドキュメントでは具体数値が確認できないため、ヘビーユースの想定ならAPI従量課金も合わせて検討。
どのプラットフォームから使うべきか
Opus 4.7は同日に多くのプラットフォームで利用可能になりました。用途別の使い分け目安は以下です。
アクセス経路 | 向いている用途 | 備考 |
|---|---|---|
Claude Pro / Max(claude.ai) | 個人・少人数の日常的なAI作業 | Web・iOS・Androidで完結。料金は月額固定 |
Claude Team / Enterprise | チーム運用・SSO・監査ログ必須の企業 | 管理者機能・コラボ機能付き |
Claude API(直接) | プロダクト組み込み・自動化 | モデルID |
Amazon Bedrock | 既にAWSを使っている企業 | モデルID |
Google Cloud Vertex AI | 既にGCPを使っている企業 | VPC-SC・IAM連携 |
Microsoft Foundry | 既にAzureを使っている企業 | AIエコシステム統合 |
GitHub Copilot | コーディング支援・IDE統合 | GA済み。料金はGitHub側の体系 |
Snowflake Cortex AI | データウェアハウス上でのAI処理 | SQLから直接呼び出し可 |
Amazon Bedrock版は Asia Pacific(Tokyo) でも当日から利用可能になっており、日本国内のデータレジデンシ要件がある企業には実務的な選択肢です。
出典: Claude Opus 4.7 on Amazon Bedrock — AWS News、GitHub Changelog
他ツール・他モデルとの違い
Claude Opus 4.7 vs Opus 4.6:乗り換えるべきか
次のいずれかに該当するなら、Opus 4.7への切り替えを検討する価値があります。
- 難しいコーディングタスク(複雑なバグ修正・大型差分レビュー)で Opus 4.6 の精度に不満がある
- 長時間エージェント運用でツール呼び出しエラー起因の巻き戻しが多い
- 画像・UIキャプチャの読解精度を上げたい
- ビジネスロジックの指示追従が「ふんわり」で悩んでいる
一方、以下に該当する場合は急いで切り替える必要はありません。
- バックグラウンドで大量の要約・分類を回している(実効コスト増のインパクトが大きい)
- 既存のOpus 4.6向けプロンプト群のリグレッションテスト工数が割けない
- 業務に求める精度はすでに満たしている
Claude Opus 4.7 vs GPT-5.4
- コーディング主体なら Opus 4.7 有利(SWE-bench Pro +6.6pt)
- 純粋な推論タスクはほぼ互角(GPQA Diamond 94.2〜94.4%)
- 料金はGPT-5.4の方が低いことが多いため、コスト最優先ならGPT-5.4も候補
- 詳細は GPT-5.4 vs Claude Opus 比較 を参照
Claude Opus 4.7 vs Gemini 3.1 Pro
- コーディング・エージェント用途は Opus 4.7 優位
- 動画理解・マルチモーダル(動画)は Gemini 3.1 Pro 優位(Video-MME 78.2%)
- 低コスト大量処理は Gemini 3.1 Pro 有利(単価がOpus 4.6の約1/5、GPT-5.4の約1/4)
- 詳細は Claude vs Gemini 比較 を参照
Claude Opus 4.7 vs Claude Mythos Preview
- Mythos PreviewはOpus 4.7より高性能だが、一般提供されていない(サイバー誤用懸念と整合性評価の結論が理由)
- Opus 4.7は「安全に公開できる範囲の最高性能」というポジション
- 現時点で使えるのはOpus 4.7まで。Mythosの公開見通しはClaude Mythosとはを参照
Claude Opus 4.7が向いている人/向いていない人
こんな方におすすめ
- 難易度の高いコーディング業務を任せたい開発者・開発チーム
- 長時間動くエージェントを本番運用したい事業担当者
- 大規模コードベースを1Mトークンのロングコンテキストで読ませたい
- 長文ドキュメント・提案書・レポートの執筆品質を重視するビジネスユーザー
- 技術図面・UIキャプチャ・密な文書画像を読ませたいユーザー
- AWS・GCP・Azureなど既存クラウド上でAIを使いたい情シス・SRE
おすすめしない方
- バックグラウンドで大量の軽作業(要約・分類・タグ付け)を低コストで回したい用途 → Gemini 3.1 ProやClaude Sonnet 4.6の方が合う
- 動画コンテンツの理解・要約が主目的 → Gemini 3.1 Proが優位
- 最小限のコストで試したい個人ユーザー → まずはClaude Sonnet 4.6や無料枠のある他モデルから
- 合成有害物質に関する安全情報を業務で扱う用途 → 公式が弱点を認めており、他ソースと併用が必要
- 攻撃的サイバーセキュリティ検証を業務で行う組織 → Cyber Verification Programの申請承認を待つか、専用ツールとの併用が必要
セキュリティ・整合性に関する公式評価
Opus 4.7は、Anthropic自身の評価で「largely well-aligned and trustworthy, though not fully ideal in its behavior」(おおむね良く整合しており信頼できるが、挙動は完全に理想的ではない)と位置づけられています。
現時点で確認できる安全関連の主な事実:
- プロンプト注入への耐性がOpus 4.6比で改善
- サイバー攻撃用途の自動ブロック機構を搭載
- 訓練段階で攻撃的サイバー能力を削減
- Cyber Verification Programで検証済みアカウントに拡張アクセスを提供
- データレジデンシ:
inference_geo: "us"指定でUS-only推論(料金1.1x)
AIの業務導入における一般的なセキュリティ観点は 生成AI セキュリティ リスク も合わせて確認してください。
よくある質問(FAQ)
Q1. Claude Opus 4.7とOpus 4.6の違いを一文で言うと?
A. ソフトウェアエンジニアリング・長時間エージェント・ビジョン入力の3領域が底上げされつつ、料金は据え置きのマイナーバージョンアップです。ただし新トークナイザーで実効コストが最大+35%増える可能性があります。
Q2. GPT-5.4より本当に性能が高いのですか?
A. コーディング系ベンチマーク(SWE-bench Pro、SWE-bench Verified、CursorBench)ではOpus 4.7が明確に上回ります。一方、GPQA Diamond(大学院レベル推論)はほぼ横並び、動画理解(Video-MME)ではGemini 3.1 Proが優位です。
Q3. Claude Mythos Previewと何が違うのですか?
A. Mythos PreviewはAnthropic内部のより高性能なモデルですが、整合性とサイバー誤用リスクを理由に一般公開されていません。Opus 4.7は「安全に公開できる範囲で最高性能」という位置づけです。
Q4. 料金がOpus 4.6と同じなら、とりあえず全部Opus 4.7に切り替えるべき?
A. 必ずしもそうではありません。新トークナイザーで同じテキストでも消費トークンが最大+35%増える可能性があるため、大量処理では実効コストが上昇することがあります。小規模トラフィックで実効コストを計測してから本番切替するのが安全です。
Q5. どのプランで使えますか?
A. Claude Pro / Max / Team / Enterprise の各プランで利用できます。API経由では従量課金(入力$5/出力$25 per MTok)です。具体的なメッセージ上限は公式のClaude料金ページで確認してください。
Q6. 日本の企業でも使えますか? データレジデンシはどうなる?
A. Amazon Bedrockの東京リージョン(Asia Pacific Tokyo)で当日から提供されており、日本国内のデータレジデンシ要件に対応しやすくなっています。また inference_geo: "us" 指定でUS-only推論(料金1.1x)も選択可能です。
Q7. Claude Codeやコーディング支援ツールからも使えますか?
A. はい。Claude Code、GitHub Copilot(GA済み)、Cursorなど主要なコーディング支援ツールでOpus 4.7が利用可能です。Claude Codeの使い方はClaude Code 使い方 ガイドを参照してください。
Q8. Opus 4.6向けのプロンプトはそのまま動きますか?
A. 動く場合が多いですが、指示追従が精密化した影響で挙動が変わるケースがあります。本番切替前にリグレッションテストを行い、必要に応じてプロンプトを再調整してください。
まとめ
Claude Opus 4.7は、2026年4月16日に一般提供開始された「一般公開モデル最強クラス」のClaude Opus系モデルです。SWE-bench Pro 64.3%でGPT-5.4・Gemini 3.1 Proを引き離し、コーディング・長時間エージェント運用・ビジョン入力の3領域が底上げされました。料金はOpus 4.6から据え置き(入力$5/出力$25 per MTok)ですが、新トークナイザーで実効コストが最大+35%増える可能性があるため、本番切替前に小規模トラフィックで必ず計測してください。
Anthropic内部にはさらに高性能な「Claude Mythos Preview」がありますが、サイバー誤用懸念から一般公開されていません。したがってOpus 4.7は、2026年4月時点で「安全に業務導入できる範囲で最高性能」という実務的な最適解です。
次に読むべき関連記事
- Claudeとは — Claudeシリーズ全体の理解を深めたい方向け
- Claude料金 — プラン別の料金・上限を判断したい方向け
- Claude Max プラン解説 — 最上位プランの検討資料
- Claude Mythosとは — Opus 4.7の上位モデルの現状
- Claude Code 使い方 ガイド — Opus 4.7をコーディング業務に組み込む
- Claude Code 料金 — Claude Code経由の料金体系
- GPT-5.4とは — 主要比較相手のGPT-5.4側の整理
- Gemini 3.1 Proとは — 動画理解で優位な比較相手
- GPT-5.4 vs Claude Opus 比較 — モデル選定の判断軸
- Claude vs Gemini 比較 — 用途別の使い分け
- 生成AIツールおすすめ比較 — Claude以外も含めた全体俯瞰
- 生成AI セキュリティ リスク — 業務導入時のセキュリティ観点
この記事の著者

AI革命
編集部
AI革命株式会社の編集部です。最新のAI技術動向から実践的な導入事例まで、企業のデジタル変革に役立つ情報をお届けしています。豊富な経験と専門知識を活かし、読者の皆様にとって価値のあるコンテンツを制作しています。
最新記事

Thinking Machines Inklingとは?Mira Murati初のオープンウェイトモデルの性能・料金・使い方を完全解説【2026年7月速報】
2026/07/16

Gemini 3.5 Proとは?性能・料金・Flash比較・Claude Opus 4.8との違い【2026年7月最新・リリース目前】
2026/06/02

警備業界のAI活用事例|監視カメラ・異常行動検知・巡回省人化で人手不足を補う導入ガイド
2026/07/16

警察・公安のAI活用事例|年齢進行顔画像・犯罪予測・疑わしい取引分析を徹底解説
2026/04/24

翻訳会社・翻訳業界のAI活用事例|MTPE・用語集運用・単価下落への対応策
2026/07/15

葬儀・葬祭業のAI活用事例|AIナレーション・デジタル供養・業務効率化を徹底解説
2026/04/23
