Qwen 3.5-Omniとは?機能・料金・3バリアントの違い・GPT-4oとの比較を解説

Qwen 3.5-Omni(通義千問3.5-Omni)は、Alibaba Cloud(アリババクラウド)が2026年3月に公開した、テキスト・画像・音声・動画を1回の推論で同時に処理できるネイティブ・マルチモーダルAIモデルです。 GPT-4oの約1/6〜1/25のAPI料金でマルチモーダル処理が可能な点と、113言語の音声認識・36言語の音声合成に対応する多言語性能の高さが注目されています。
この記事では、以下の内容を整理しています。
- Qwen 3.5-Omniの基本的な仕組みとアーキテクチャ
- テキスト・画像・音声・動画それぞれでできること
- 3つのバリアント(Plus / Flash / Light)の違いと選び方
- DashScope APIの料金とGPT-4o・Geminiとのコスト比較
- セキュリティ・データ主権に関する注意点
- こんな方におすすめ/おすすめしないケース
マルチモーダルAIの導入を検討している方や、GPT-4oやGeminiからの乗り換え・併用を考えている開発者・ビジネスユーザー向けの記事です。
Qwen 3.5-Omniとは — テキスト・画像・音声・動画を一括処理するマルチモーダルAI
Qwen 3.5-Omniは、Alibaba CloudのQwen(通義千問)チームが開発したネイティブ・マルチモーダル大規模言語モデルです。「ネイティブ・マルチモーダル」とは、テキストモデルに音声や画像の処理機能を後から追加したのではなく、最初からすべてのモダリティを統合して学習・処理するよう設計されていることを意味します。
項目 | 内容 |
|---|---|
正式名称 | Qwen3.5-Omni |
開発元 | Alibaba Cloud Qwen Team(アリババクラウド通義千問チーム) |
リリース日 | 2026年3月30日 |
提供形態 | API(DashScope)/ オープンウェイト(Light版)/ Webデモ(Qwen Chat) |
対応入力 | テキスト・画像・音声・動画 |
対応出力 | テキスト・リアルタイム音声 |
コンテキストウィンドウ | 256,000トークン |
公式サイト | |
API管理 |
前世代Qwen3-Omniからの主な進化
Qwen 3.5-Omniは、前世代のQwen3-Omniから大幅に機能が拡張されています。
項目 | Qwen3-Omni | Qwen3.5-Omni |
|---|---|---|
音声認識言語 | 19言語 | 113言語・方言(74言語+39の中国方言) |
音声合成言語 | 10言語 | 36言語(29言語+7つの中国方言) |
音声クローニング | 非対応 | 対応(10〜30秒の音声サンプルから複製) |
セマンティック割り込み | 非対応 | 対応(相槌と発話意図の区別) |
ARIA技術 | なし | 搭載(数字・単語の発音精度向上) |
Audio-Visual Vibe Coding | なし | 対応(動画を見ながらコード生成) |
ライセンス | Apache 2.0(完全オープンソース) | Plus/Flashはクローズド、Lightはオープンウェイト |
Thinker-Talkerアーキテクチャ
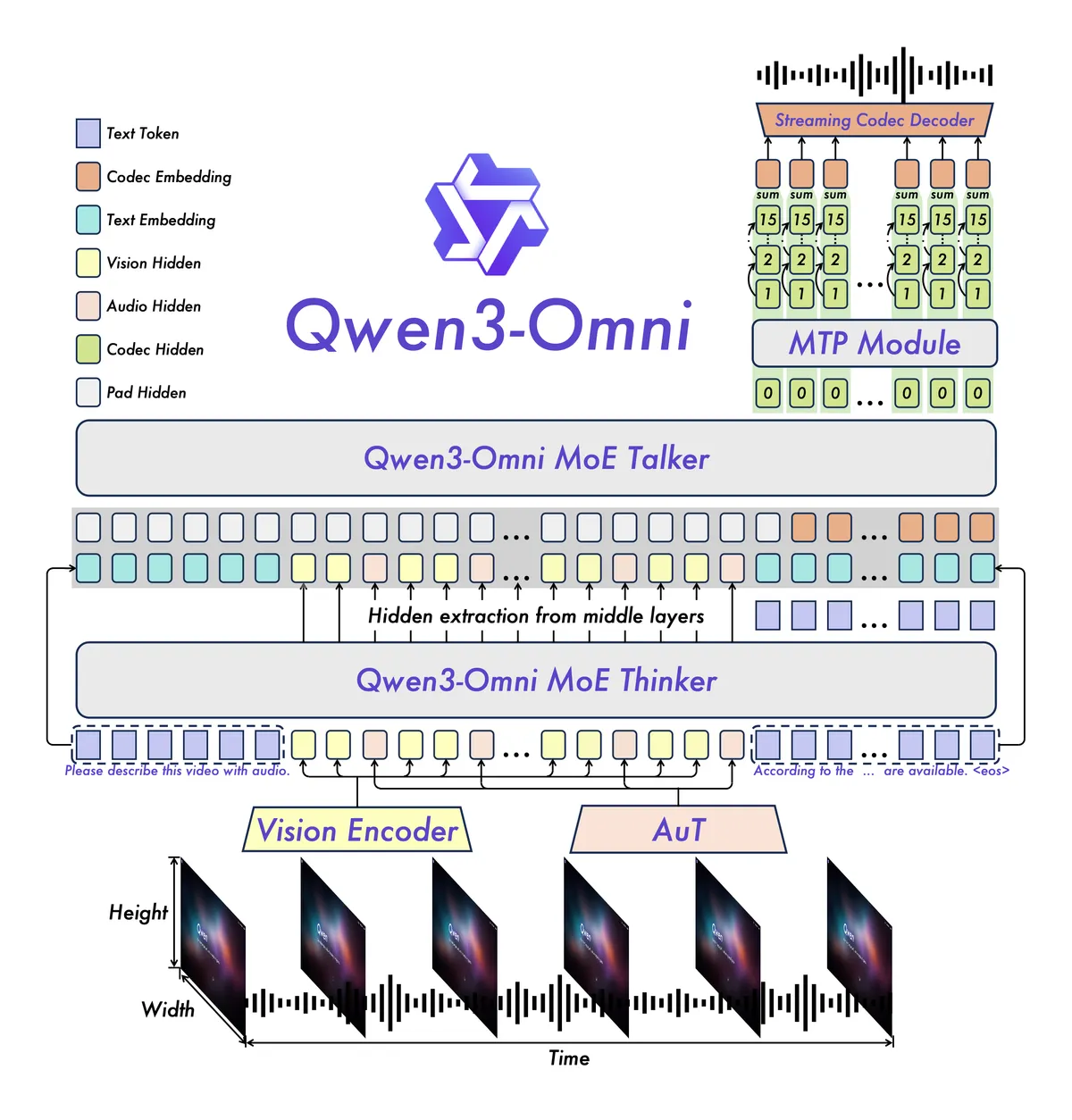
Qwen 3.5-Omniは「Thinker-Talker」と呼ばれる2モジュール構成を採用しています。
- Thinker(思考モジュール): テキスト・画像・音声・動画のすべてのモダリティを受け取り、推論とテキスト生成を行う
- Talker(発話モジュール): Thinkerが生成した意味表現を、ストリーミング音声トークンに変換して出力する
この分離設計の利点は、ThinkerとTalkerの間にセーフティフィルタやRAGパイプライン、関数呼び出しの処理を挟めることです。音声出力の前に安全性チェックを入れられるため、不適切な出力を防ぎやすくなっています。
両モジュールにはHybrid-Attention MoE(Mixture of Experts:混合エキスパート) が採用されており、各トークンに対してパラメータの一部だけを活性化するスパース構造により、推論コストを抑えながら高い性能を実現しています。
Qwen 3.5-Omniでできること — 機能一覧
Qwen 3.5-Omniの機能は多岐にわたります。できることとできないことを整理します。
対応する入出力
モダリティ | 入力 | 出力 |
|---|---|---|
テキスト | ✅ 多言語対応 | ✅ 多言語対応 |
画像 | ✅ 写真・図表・スクショ・手書きスケッチ | ❌ 画像生成は不可 |
音声 | ✅ 113言語・方言 | ✅ リアルタイム音声合成(36言語・50種の声) |
動画 | ✅ 720p/1FPSで400秒超の分析 | ❌ 動画生成は不可 |
重要な注意点: Qwen 3.5-Omniは画像や動画の生成はできません。テキストと音声の生成に特化したモデルです。画像生成が必要な場合は、別の画像生成モデルを組み合わせる必要があります。
主要機能の詳細
音声クローニング
10〜30秒の音声サンプルを入力するだけで、その声質を複製して応答を生成できます。カスタマーサポートや社内向け音声ガイドなど、特定の声での応答が必要な場面で活用できます。ただし、API経由でのみ利用可能で、Qwen ChatのWebインターフェースからは使えません。
セマンティック割り込み
相槌(「うん」「はい」など)と実際の発話意図を区別する機能です。ユーザーが相槌を打っただけなのか、新しい質問をしようとしているのかを判別し、全二重(Full-duplex)の自然な会話を実現します。
Audio-Visual Vibe Coding
動画やスクリーン録画を視聴しながら、音声での指示を聞いてコードを生成できます。たとえば、手書きスケッチの写真を見せて「これをReactページにして」と話しかけるだけでコードが出力されます。
リアルタイムWeb検索
外部のWeb検索機能がネイティブに統合されており、最新情報を取得しながら回答を生成できます。
関数呼び出し(Function Calling)
外部APIとの連携に対応しています。天気情報の取得、データベースの操作、外部サービスの呼び出しなど、AIの応答と外部システムを組み合わせたワークフローを構築できます。
長時間音声処理
256,000トークンのコンテキストウィンドウにより、10時間以上の連続音声や720p/1FPSで400秒超の動画を1回のリクエストで処理できます。長時間の会議録音や講義の分析などに有用です。
3つのバリアント(Plus / Flash / Light)の違いと選び方
Qwen 3.5-Omniは、用途とコストに応じて3つのバリアントから選択できます。
項目 | Plus | Flash | Light |
|---|---|---|---|
位置づけ | フラッグシップ(最高性能) | バランス型(速度×品質) | 軽量版(コスト重視) |
アーキテクチャ | 大規模MoE | 軽量MoE | 小規模密集型 |
提供形態 | API限定 | API限定 | オープンウェイト(Hugging Face) |
セルフホスト | ❌ 不可 | ❌ 不可 | ✅ 可能 |
テキスト入力料金 | $0.43/100万トークン | $0.10/100万トークン | 無料(セルフホスト時) |
推奨用途 | 高精度が必要な製品・音声エージェント | 本番環境のデフォルト | エッジデバイス・プロトタイプ・データ完全管理 |
GPU要件 | 高い(A100 80GB以上) | 中程度 | 比較的低い |
どのバリアントを選ぶべきか
Plus を選ぶべきケース
- 音声エージェント製品を開発しており、最高精度が必要
- ドキュメント理解・音声認識の品質が最優先
- ベンチマークスコアで他社モデルと同等以上の性能が必要
Flash を選ぶべきケース(多くの場合のデフォルト推奨)
- 本番環境でレイテンシと品質のバランスが重要
- コストを抑えつつ実用的な精度を確保したい
- まずは試してみたい(無料枠あり)
Light を選ぶべきケース
- データを外部に出したくない(セルフホスティング必須)
- エッジデバイスやローカル環境で動作させたい
- APIコストをゼロにしたい
- プロトタイプや概念検証段階
Qwen 3.5-Omniの強み
1. 圧倒的なコストパフォーマンス
Qwen 3.5-Omniの最大の強みは、GPT-4oやGeminiと比較して大幅に低いAPI料金です。テキスト入力でGPT-4oの約1/6(Plus)〜1/25(Flash)、音声入力ではGPT-4o Realtimeの約1/8の料金で利用できます。
マルチモーダルAIをAPIで大量に処理する場合、この価格差は月額コストに直結します。
2. ネイティブ・マルチモーダルの処理速度
従来のマルチモーダル処理では、動画からフレームを抽出し、音声を文字起こしし、OCRで文字を読み取り、それぞれの結果を統合する――という多段パイプラインが一般的でした。Qwen 3.5-Omniはこれを1回の推論で一括処理します。
実際のテストでは、ChatGPT 5.4が動画分析に約9分かかったタスクを、Qwen 3.5-Omniは約1分で処理したとの報告があります(メディア「Decrypt」による比較事例)。
3. 多言語音声の安定性
音声合成の安定性を測るSeed-zhベンチマークでは、Qwen 3.5-Omni Plusのスコアは1.07。これはElevenLabs(13.08)やGemini 2.5 Pro(2.42)を大幅に上回る数値です(低いほど安定)。吃音や不自然な反復が少なく、自然な発話品質を実現しています。
4. 主要ベンチマークでの高い性能
公式発表(Plus版)のベンチマーク結果を一部抜粋します。
ベンチマーク | Qwen3.5-Omni Plus | 比較対象 |
|---|---|---|
MMAU(音声理解) | 82.2 | Gemini 3.1 Pro: 81.1 |
MuchoMusic(音楽理解) | 72.4 | Gemini 3.1 Pro: 59.6 |
VoiceBench(音声対話) | 93.1 | Gemini 3.1 Pro: 88.9 |
OmniDocBench(文書理解) | 90.8 | GPT-5.2: 85.7 / Claude Opus 4.5: 87.7 |
MMMU(マルチモーダル理解) | 82.0% | GPT-4o: 79.5% |
HumanEval(コード生成) | 92.6% | GPT-4o: 89.2% |
LibriSpeech WER(音声認識) | 1.7% | GPT-4o: 2.2% |
公式発表では215のベンチマークでSOTA(最先端) を達成したとされています。特に音声・音声動画理解・推論・インタラクション分野での性能が際立っています。
5. 1億時間超のデータで事前学習
Qwen 3.5-Omniは1億時間以上のオーディオ・ビジュアルデータで事前学習されています。テキストモデルに音声を後付けするのではなく、最初からマルチモーダルデータで学習しているため、モダリティ間の理解がより自然です。
Qwen 3.5-Omniの弱み・注意すべき制約
強みがある一方で、導入前に理解しておくべき制約もあります。
1. 画像・動画の生成はできない
Qwen 3.5-Omniが出力できるのはテキストと音声のみです。画像生成や動画生成が必要な場合は、DALL-Eなど別の生成モデルを組み合わせる必要があります。
2. Plus / Flashがクローズドソースに
前世代のQwen3-OmniはApache 2.0ライセンスで完全オープンソースでしたが、Qwen 3.5-OmniではPlus版とFlash版がクローズドソース(API限定)に変更されました。
この方針転換により、セルフホスティングでデータを完全管理したい場合の選択肢がLight版のみに限定されます。性能面ではPlusが最も優れていますが、データを外部に出せない環境ではLight版で妥協するか、前世代のQwen3-Omniを使う判断になります。
3. コンテキストウィンドウの制約
256,000トークンのコンテキストウィンドウは十分に大きいものの、Gemini 2.5 Pro(100万トークン)やGemini 3.1 Pro(200万トークン)と比較すると見劣りします。超長文の文書処理や、非常に長い動画の一括分析が必要な場合はGeminiの方が適しています。
4. ソフトウェアエンジニアリングタスクでの限界
コード生成のHumanEvalでは高いスコアを記録していますが、実際のソフトウェアプロジェクト全体を扱うSWE-bench系のタスクでは、Claude Opus 4.5(80%以上)に対して劣位と見られています。大規模なコードベース全体のリファクタリングや複雑なバグ修正には、Claudeの方が適している場面があります。
5. GPU要件の高さ(Light版セルフホスト時)
Light版をセルフホスティングする場合、vLLM 0.13.0以上での推論が推奨されています。HuggingFace Transformersでの推論は低速であり、実用的な速度を得るにはGPU環境の整備が必要です。Plus版相当の性能を出すにはA100 80GB以上が最低要件とされています。
6. 数学的精度に課題
複雑な税計算などの正確な数値処理で誤りが報告されています。数値の厳密性が求められるタスクでは、出力結果を必ず検証する必要があります。
料金・プラン — DashScope API料金表
Qwen 3.5-OmniはDashScope(Alibaba Cloud Model Studio)のAPIとして提供されています。現時点の料金は以下の通りです。
International(シンガポールリージョン)の料金
項目 | Plus | Flash |
|---|---|---|
テキスト/画像/動画 入力 | $0.43/100万トークン | $0.10/100万トークン |
音声入力 | $3.81/100万トークン | $0.40/100万トークン |
テキスト出力(テキスト入力時) | $1.66/100万トークン | $0.40/100万トークン |
テキスト出力(マルチモーダル入力時) | $3.06/100万トークン | — |
テキスト+音声出力 | $15.11/100万トークン | — |
他社モデルとのテキスト入力料金比較
モデル | テキスト入力料金(100万トークンあたり) | Plusとの倍率 |
|---|---|---|
Qwen3.5-Omni Flash | $0.10 | 0.2倍 |
Qwen3.5-Omni Plus | $0.43 | 1倍(基準) |
Gemini 2.5 Pro(≤200K) | $1.25 | 約3倍 |
GPT-4o | $2.50 | 約6倍 |
音声入力でも差は顕著です。GPT-4oのRealtime音声が$32/100万トークンであるのに対し、Qwen3.5-Omni Plusの音声入力は$3.81と約8倍の価格差があります。
料金に関する補足
- 無料枠: 新規DashScopeアカウント(シンガポールリージョン)は、入力100万トークン+出力100万トークンが無料(90日間有効)
- 段階料金制: Flash版ではコンテキスト長に応じて料金が段階的に上がる。長いコンテキストの利用が多い場合は注意
- バッチ処理割引: リアルタイム推論の50%割引が適用されるバッチ処理に対応(ただしコンテキストキャッシュとの併用不可)
- 中国本土リージョン: 北京リージョンではさらに約40%安い料金設定
- Light版: オープンウェイトのためセルフホスティング時はAPI料金不要
月額コストの目安
実際の利用シナリオでの参考値です(Plusモデル、Internationalリージョン)。
利用シナリオ | 月間トークン数(目安) | 月額料金(目安) |
|---|---|---|
日常的なテキスト質問応答(1日100回) | 入出力合計 約300万トークン | 約$3〜6 |
1日2時間の音声処理 | 入力 約3,600万トークン | 約$137 |
動画分析(1日30分) | 入力 約1,000万トークン | 約$4.3 |
※ 実際の料金はリクエスト内容、コンテキスト長、出力モダリティにより変動します。
使い方・始め方
Qwen 3.5-Omniを使い始める方法は4つあります。
1. Qwen Chat(最も手軽)
qwen.ai のWebインターフェースで直接試用できます。アカウント登録のみで、API設定不要でテキスト・画像・音声の入出力を体験できます。ただし、音声クローニングなど一部のAPI限定機能は使えません。
2. DashScope API(本番環境向け)
Alibaba Cloud Model Studio経由でAPIを利用します。OpenAI互換のインターフェースに対応しているため、既存のOpenAI SDKベースのコードからの移行が容易です。
モデルID:
- qwen3.5-omni-plus
- qwen3.5-omni-flash
- qwen3.5-omni-light
リージョンは以下の3つから選択できます。
- International(シンガポール): 無料枠あり。推論は中国本土を除くグローバルで分散
- Global(米国バージニア or ドイツフランクフルト): データ主権が重要な場合に選択。無料枠なし
- 中国本土(北京): 中国国内向け。料金が最も安い
3. Hugging Face デモ
Hugging Faceのデモページでオンライン試用できます。環境構築不要でモデルの性能を確認できます。
4. セルフホスティング(Light版のみ)
Light版はHugging Faceからウェイトをダウンロードしてセルフホスティングできます。
推奨環境:
- vLLM 0.13.0以上
- pip install transformers==4.57.3
- pip install qwen-omni-utils -U
セルフホスティングのメリットは、データが外部に送信されない完全なプライバシー管理と、API料金ゼロの運用です。ただし、GPU環境の整備と運用コストは自己負担になります。
他のAIモデルとの比較
Qwen 3.5-Omniを検討する際に比較対象になる主要モデルとの違いを整理します。
総合比較表
比較項目 | Qwen3.5-Omni Plus | GPT-4o | Gemini 2.5 Pro | Claude Opus 4.5 |
|---|---|---|---|---|
開発元 | Alibaba Cloud | OpenAI | Google DeepMind | Anthropic |
テキスト入力料金 | $0.43 | $2.50 | $1.25 | $15.00 |
コンテキストウィンドウ | 256K | 128K | 100万 | 200K |
音声入力 | ✅ 113言語 | ✅ | ✅ | ❌ |
音声出力 | ✅ 36言語 | ✅ | ✅ | ❌ |
画像入力 | ✅ | ✅ | ✅ | ✅ |
画像生成 | ❌ | ✅ | ✅ | ❌ |
動画入力 | ✅ | ✅(フレーム抽出) | ✅ | ❌ |
音声クローニング | ✅ | ❌ | ❌ | ❌ |
セルフホスト | ✅(Light版) | ❌ | ❌ | ❌ |
日本語対応 | ✅(音声認識含む) | ✅ | ✅ | ✅(テキストのみ) |
GPT-4oとの比較
Qwen 3.5-Omniが優れている点:
- テキスト入力料金が約1/6、音声入力料金が約1/8
- 動画をネイティブに一括処理できる(GPT-4oはフレーム抽出が必要な場面がある)
- 音声クローニング機能がある
- Light版によるセルフホスティングが可能
- MMMU・HumanEval・LibriSpeech等のベンチマークで上回る
GPT-4oが優れている点:
- 画像生成に対応
- SWE-bench系の実務的なソフトウェアエンジニアリングタスク
- プラグインエコシステムの充実度
- 日本語での会話品質の安定性(実績が豊富)
- 米国企業のサービスであることによるデータ主権の安心感
Gemini 2.5 Pro / 3.1 Proとの比較
Qwen 3.5-Omniが優れている点:
- API料金が大幅に安い(テキスト入力で約1/3)
- 音声認識の対応言語数(113 vs Geminiの公開数)
- 音声合成の安定性(Seed-zhスコアで大差)
- 音声クローニング機能
- セルフホスティングオプション
Geminiが優れている点:
- コンテキストウィンドウが圧倒的に大きい(100万〜200万トークン)
- 画像生成・動画生成に対応
- Googleサービス(Gmail、Docs等)との統合
- Google検索との深い連携
Claude Opus 4.5との比較
Qwen 3.5-Omniが優れている点:
- 音声の入出力に対応(Claudeはテキスト専用)
- 動画入力に対応
- API料金が約1/35(テキスト入力ベース)
- ドキュメント理解ベンチマーク(OmniDocBench)で上回る
Claudeが優れている点:
- ソフトウェアエンジニアリングタスク(SWE-bench 80%以上)
- 長文の文章作成・分析の品質
- コードベース全体の理解と修正
- セキュリティ・安全性の設計思想
セキュリティとデータ主権に関する注意点
Qwen 3.5-Omniの導入を検討する際、セキュリティとデータ主権は重要な判断材料です。特に中国企業(アリババ)のサービスであることを踏まえた検討が必要です。
データ処理リージョンの選択肢
DashScope APIは3つのリージョンを提供しており、データの保管場所を選択できます。
リージョン | データ保管場所 | 推論実行場所 | 無料枠 |
|---|---|---|---|
International | シンガポール | 中国本土を除くグローバル | あり |
Global(米国) | バージニア | グローバル分散 | なし |
Global(ドイツ) | フランクフルト | グローバル分散 | なし |
中国本土 | 北京 | 中国本土 | あり |
データ主権に敏感な組織は、Global(米国またはドイツ)リージョンを選択するか、Light版のセルフホスティングを検討してください。
公式のセキュリティ対応
Alibaba Cloudの公式見解として、以下が明示されています。
- 企業の入力データはAIモデルの再学習に使用されない
- 専用VPCネットワーク・PrivateLinkに対応(機密情報の安全な取り扱い)
- Thinker-Talker分離設計により、音声出力前にセーフティフィルタを挿入可能
- エンタープライズグレードのセキュリティ環境を提供
導入時に検討すべきこと
- 社内のセキュリティポリシーとの整合: 中国企業のクラウドサービスの利用が許可されているか確認
- データの機密度: 機密性の高いデータを扱う場合は、Light版のセルフホスティングが最も安全
- コンプライアンス要件: GDPR等の規制要件がある場合は、Globalリージョン(ドイツ)の利用やセルフホスティングを検討
- ハイブリッド運用: 機密データはClaude/GPTで処理し、音声・動画処理など大量のマルチモーダルデータはQwenで処理する、といった使い分けも有効
こんな方におすすめ / おすすめしない方
Qwen 3.5-Omniがおすすめな方
- 音声・動画を大量にAPI処理する開発者: GPT-4oと比較して1/6〜1/8のコストで運用できる
- 多言語の音声対応が必要な製品を開発中: 113言語の音声認識と36言語の音声合成は業界最広
- アジア言語(日本語・中国語・韓国語等)の音声処理が中心: Qwenはアジア言語のデータが豊富
- マルチモーダルAIをなるべく安く試したい方: Flash版なら$0.10/100万トークン + 無料枠あり
- データを外部に出せない環境で利用したい方: Light版のセルフホスティングが可能
- 動画からの情報抽出を高速に行いたい方: ネイティブ処理のため多段パイプラインが不要
おすすめしない方
- 大規模なソフトウェアエンジニアリングタスクが中心: SWEタスクではClaude Opus 4.5やClaude Codeの方が実績がある
- 画像生成や動画生成も必要: Qwen 3.5-Omniは生成非対応。GPT-4oやGeminiの方が適している
- 100万トークン超の超長文を一括処理したい: Gemini 2.5 Pro以上のコンテキストが必要
- 中国企業のサービス利用がセキュリティポリシー上不可: Light版セルフホストでも社内規定に抵触する場合は代替を検討
- 日本語での会話品質を最重視: テキスト応答の日本語品質は、ChatGPTやClaudeの方が実績豊富
よくある質問(FAQ)
Q1. Qwen 3.5-Omniは日本語に対応していますか?
テキストの入出力は日本語に対応しています。音声認識では113言語・方言をサポートしており、日本語も含まれると見られます。ただし、日本語音声の認識精度や合成品質について公式の個別データは公開されていないため、利用前にQwen ChatやAPI無料枠で実際の精度を確認することをおすすめします。
Q2. 無料で使えますか?
はい、複数の方法で無料利用できます。Qwen Chat(qwen.ai)ではアカウント登録のみで試用できます。DashScope APIもInternationalリージョンの新規アカウントに入力100万+出力100万トークンの無料枠(90日間)があります。Light版をセルフホスティングすればAPI料金は完全に無料です。
Q3. GPT-4oとどちらを選ぶべきですか?
用途によります。音声・動画のマルチモーダル処理が中心でコストを重視するならQwen 3.5-Omni、画像生成も含めた総合的なAIプラットフォームが必要ならGPT-4oが適しています。両者を併用し、大量のマルチモーダル処理はQwen、精度が重要なテキスト処理はGPTと使い分ける方法もあります。
Q4. 前世代のQwen3-Omniとの主な違いは?
音声認識言語が19→113に、音声合成言語が10→36に大幅拡大されました。加えて、音声クローニング、セマンティック割り込み、ARIA技術、Audio-Visual Vibe Codingなどの新機能が追加されています。ただし、Plus/Flashがクローズドソースになった点は前世代からの大きな変更です。
Q5. Qwen3.6-Plusとの違いは?
2026年4月時点で、後継のQwen3.6-Plusがプレビュー段階にあるとの情報があります。Qwen3.6-Plusは100万トークンのコンテキストウィンドウとエージェントコーディング特化を目指しているとされますが、正式リリース前のためスペックは未確定です。Qwen 3.5-Omniは現行のオムニモーダル最新版で、音声・動画処理が必要な場合はこちらが該当します。
Q6. データは中国に送信されますか?
リージョンの選択によります。Internationalモード(シンガポール)やGlobalモード(米国/ドイツ)を選択した場合、データは中国本土では保管されません。中国本土リージョンを選ばない限り、データは選択したリージョンで処理されます。さらにデータ管理を厳格にしたい場合は、Light版のセルフホスティングを検討してください。
まとめ
Qwen 3.5-Omniは、テキスト・画像・音声・動画をネイティブに一括処理できるマルチモーダルAIモデルです。GPT-4oと比較して1/6〜1/25の料金設定と、113言語対応の音声認識、音声クローニング機能などが大きな差別化ポイントです。
一方で、画像・動画の生成には非対応であること、Plus/Flashがクローズドソースになったこと、中国企業のサービスであるためデータ主権の検討が必要な点は、導入前に理解しておくべきポイントです。
音声・動画のマルチモーダル処理をコスト効率よく大量に行いたい場面では有力な選択肢です。一方、テキスト中心の高精度な推論やソフトウェアエンジニアリングが主な用途であれば、Claude Opus 4.5やClaude Codeの方が適しています。
関連記事
AIモデルの比較検討をさらに進めたい方は、以下の記事もあわせてご覧ください。
この記事の著者

AI革命
編集部
AI革命株式会社の編集部です。最新のAI技術動向から実践的な導入事例まで、企業のデジタル変革に役立つ情報をお届けしています。豊富な経験と専門知識を活かし、読者の皆様にとって価値のあるコンテンツを制作しています。
関連記事



